


SPARQL point: Was ist das und wie benutzt man es
Das Open-Data-Portal des Cabildo de Tenerife enthält einen SPARQL-Punkt, der die Abfrage von Datensätzen ermöglicht, die ein bestimmtes Wort oder bestimmte Ressourcen enthalten.
SPARQL(SPARQL Protocol and RDF Query Language) ist eine Abfragesprache zum Abrufen und Bearbeiten von Daten, die im RDF-Format (Resource Description Framework) gespeichert sind, einem Standard zur Darstellung von Informationen im semantischen Web.
Das Tool, das zur Speicherung und Abfrage dieser Daten verwendet wird, ist Virtuoso, das die Daten in Form von RDF-Graphen speichert, die aus Subjekt-Prädikat-Objekt-Tripeln bestehen, welche die Beziehungen zwischen Entitäten und die Werte, die sie für bestimmte Eigenschaften haben, darstellen.
Im Folgenden werden wir genauer erklären, was es ist und wie es verwendet wird.
ZUGRIFF AUF DEN SPARQL POINT
Um auf den SPARQL Point des Portals datos.tenerife.es zuzugreifen, müssen Sie die Registerkarte Daten, die sich im oberen linken Teil der Startseite befindet, aufrufen.

Nach dem Zugriff auf den SPARQL-Punkt erscheint ein Bildschirm mit verschiedenen Optionen, mit denen Sie Ihre Suche eingrenzen können.
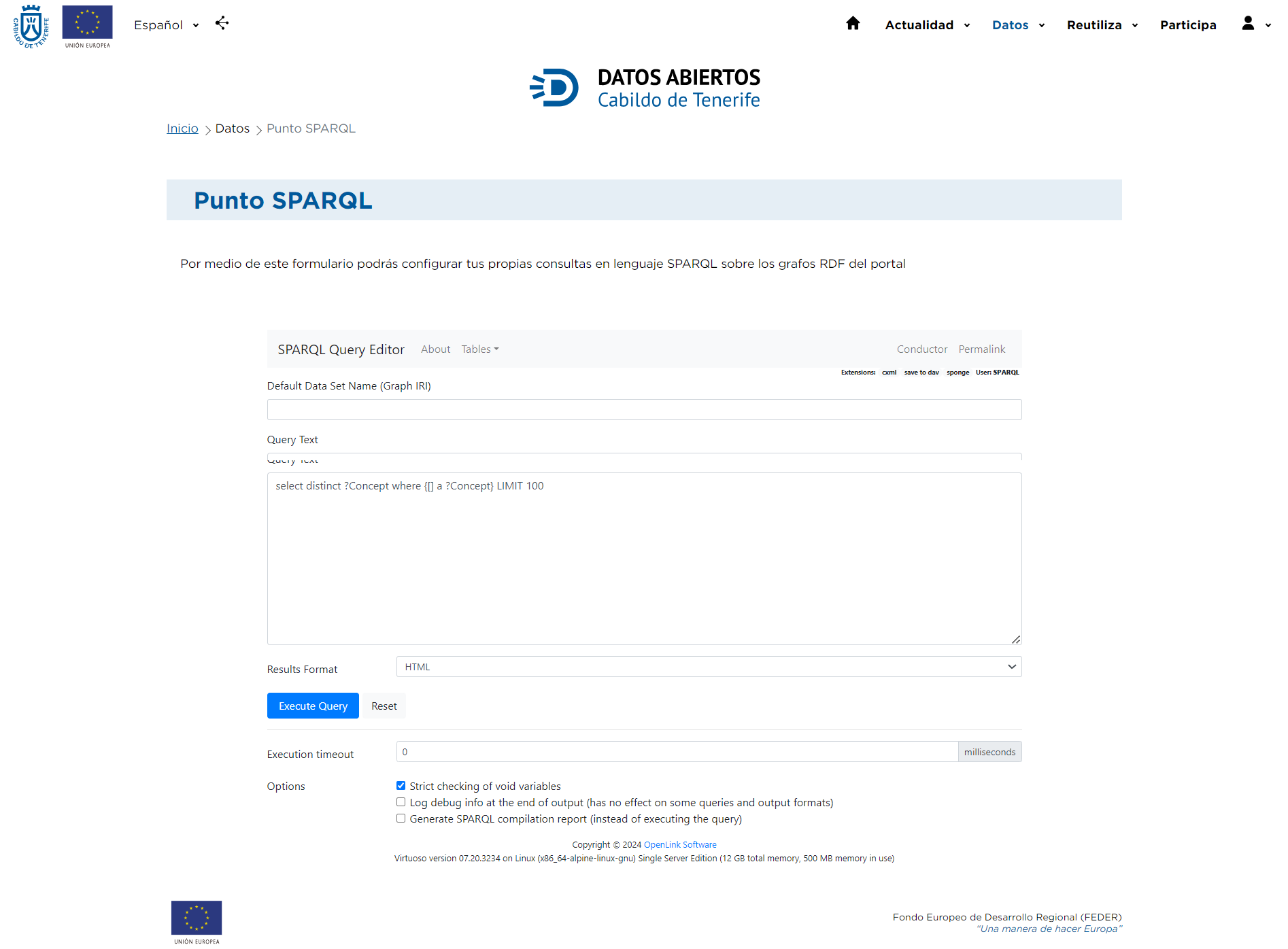
Mit SPARQL ist es möglich, komplexe Abfragen zu erstellen, die Elemente zueinander in Beziehung setzen, indem die RDF-Graphenstruktur genutzt wird. Die SPARQL-Syntax ähnelt der von SQL-Abfragen, da sie aus den Operatoren SELECT, WHERE, FILTER, ORDER BY usw. besteht.
Sie enthält eine Reihe von Präfixen(PREFIX), die dazu dienen, lange URIs(Uniform Resource Identifier) abzukürzen und Abfragen lesbarer und kompakter zu machen.
In das Feld Abfragetext können Sie die gewünschten Abfragen unter Beachtung der in den folgenden Punkten erläuterten Hinweise eingeben und durch Klicken auf die Schaltfläche Abfrage ausführen ausführen. Sobald die Abfrage ausgeführt wurde, wird das Ergebnis in einer neuen Registerkarte angezeigt. Um eine weitere Abfrage zu starten, verwenden Sie entweder den Zurück-Button des Browsers oder klicken Sie auf die SPARQL | HTML5 Tabellenoptionen. Durch Klicken auf die Schaltfläche Zurücksetzen löschen wir schließlich die eingegebene Abfrage und sehen die Beispielabfrage.
Andererseits können Sie im SPARQL Point des Open Data Portals des Cabildo das Format wählen, in dem Sie die Ergebnisse der Abfrage erhalten möchten, indem Sie die verschiedenen Werte im Dropdown-Menü Ergebnisformat" verwenden: Auto, HTML, SpreadSheet, XML, JSON, Javascript, Turtle, RDF/XML, N-Triples, CSV und TSV.
Darüber hinaus können Sie am unteren Rand der Seite zwischen drei verschiedenen Optionen wählen:
- Strenge Prüfung von ungültigen Variablen: Wenn Sie eine SPARQL-Abfrage ausführen, können Sie Variablen verwenden, denen kein Wert zugewiesen ist (ungültige Variablen). Diese Option gibt an, ob Sie möchten, dass das System eine strenge Prüfung dieser Variablen durchführt, um sicherzustellen, dass sie nicht falsch oder unangemessen in Ihrer Abfrage verwendet werden. Wenn Sie diese Option aktivieren, kann das System einen Fehler ausgeben, wenn es leere Variablen findet, die nach den Abfrageregeln nicht vorhanden sein sollten.
- Debug-Informationen am Ende der Ausgabe protokollieren: Diese Option legt fest, dass, wenn sie aktiviert ist, Debug-Details am Ende der Abfrageausgabe protokolliert werden. Debugging-Informationen enthalten normalerweise interne Details des Abfrageausführungsprozesses und können nützlich sein, um Probleme zu identifizieren oder zu verstehen, wie die Abfrage verarbeitet wird. Beachten Sie jedoch, dass diese Option für einige Abfragen oder bestimmte Ausgabeformate nicht effektiv ist.
- SPARQL Kompilierungsbericht generieren: Anstatt die SPARQL-Abfrage auszuführen, zeigt diese Option an, dass ein Bericht generiert wird, der zeigt, wie die Abfrage intern kompiliert oder verarbeitet wird. Dieser Bericht kann nützlich sein, um die Leistung oder Effizienz der Abfrage zu verstehen, ohne sie vollständig ausführen zu müssen. Er kann helfen, mögliche Optimierungen vor der eigentlichen Ausführung zu identifizieren.
SPARQL PUNKT VERWENDEN
Um SPARQL zu verstehen, ist es am besten, ein Beispiel zu verwenden und es Stück für Stück zu erklären.
Nehmen wir an, wir haben eine Reihe von RDF-Graphen, die Informationen oder Metadaten über veröffentlichte Datensätze und Ressourcen beschreiben, mit Informationen über Titel, Beschreibung, Herausgeber, Format usw.
In diesem Fall würden wir eine einfache SPARQL-Abfrage durchführen, um die ersten hundert Datensätze oder Ressourcen und ihre Links sortiert nach Titel zu erhalten:
PREFIX dct: <http://purl.org/dc/terms/> Select distinct ?URL ?title where { ?URL dct:title ?title } order by desc(?title) LIMIT 100Die Erklärung des Codes lautet wie folgt:
- PREFIX: Dieses Präfix weist der Basis-URI " http://purl.org/dc/terms/" den Alias"dct" zu. Es wird verwendet, um die URIs in der Abfrage abzukürzen.
- SELECT: Gibt die Variablen an, die wir in den Abfrageergebnissen abrufen wollen. In diesem Fall wollen wir die ersten hundert Datensätze oder Ressourcen mit ihren URLs abrufen. Die distinct-Klausel stellt sicher, dass nur eindeutige Ergebnisse angezeigt werden (keine Wiederholungen).
- WHERE: Definiert das RDF-Triple-Muster, nach dem im Netzwerk gesucht werden soll:
- ?URL dct:title ?title: Hier wird nach Triples gesucht, bei denen ein Satz einen Titel hat. Die Variable ?title wird zur Darstellung dieser Titel verwendet.
Wir können auch jede andere Art von Information erhalten, die wir in der RDF haben, Beschreibung, Herausgeber...
Auf diese Weise würde uns die SPARQL-Abfrage Ergebnisse wie die folgenden liefern:
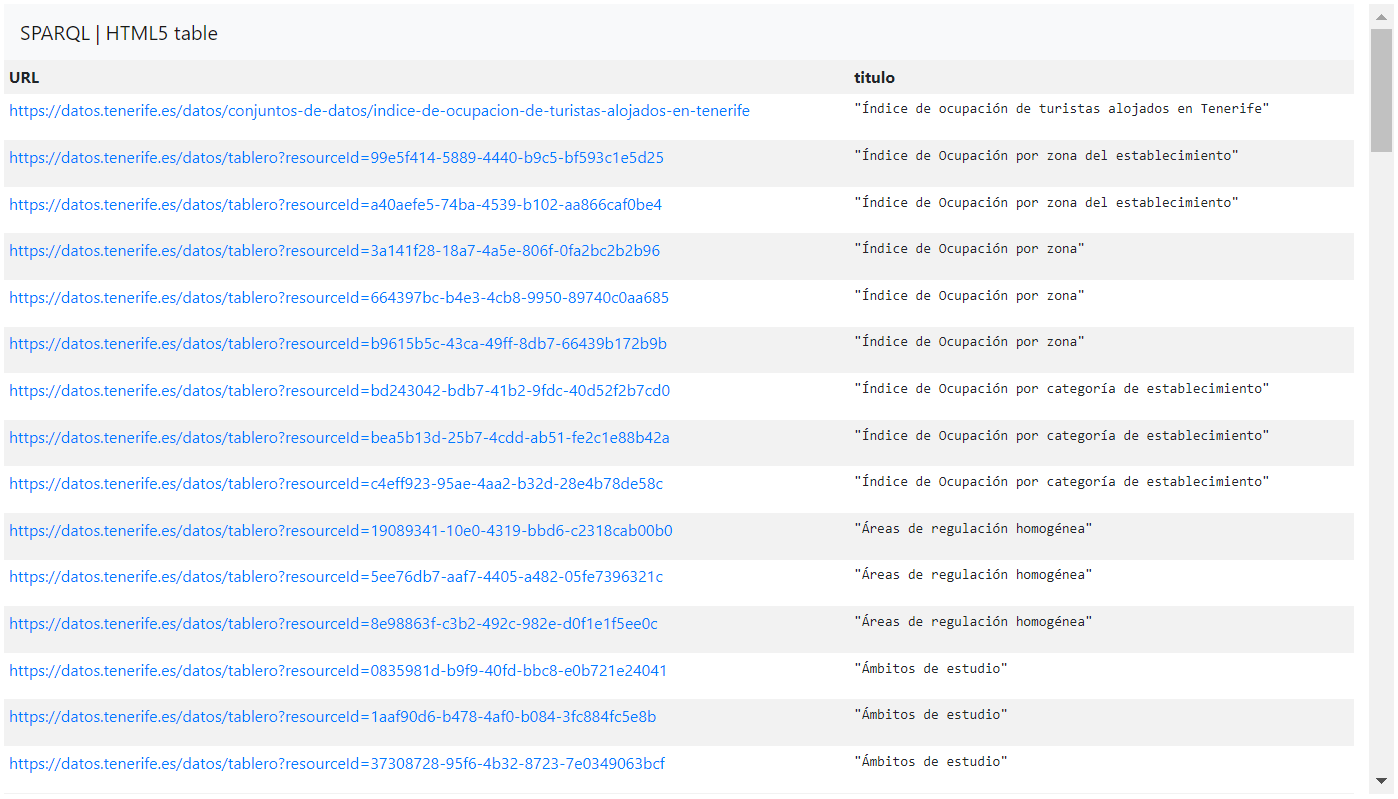
Anhand des Open Data Portals des Cabildo de Tenerife zeigen wir eine Reihe von Beispielen für SPARQL-Abfragen, um Informationen über die veröffentlichten Daten abzurufen.
In diesem Fall stützt sich Virtuoso auf den Metadatenkatalog des Portals, der unter https://datos.tenerife.es/es/datos/tablero?resourceId=17e64992-df93-4c8d-b9a5-5c860b1e978c zur Verfügung gestellt wird, um die Metadaten der veröffentlichten Datensätze und Ressourcen zu erhalten und die RDF-Graphen zu erstellen.
BEISPIELE
Im Folgenden werden anhand von Beispielen die verschiedenen Arten der Suche, die im Portal durchgeführt werden können, erläutert.
- Abrufen des Namens und des Links aller Datensätze und Ressourcen des Portals: Aufdiese Weise können Sie den Namen und den Link (URL) aller im Portal veröffentlichten Datensätze und ihrer Ressourcen (Verteilungen) abrufen .
PREFIX dct: <http://purl.org/dc/terms/> SELECT distinct ?name ?name ?URL WHERE{ ?URL dct:title ?name }
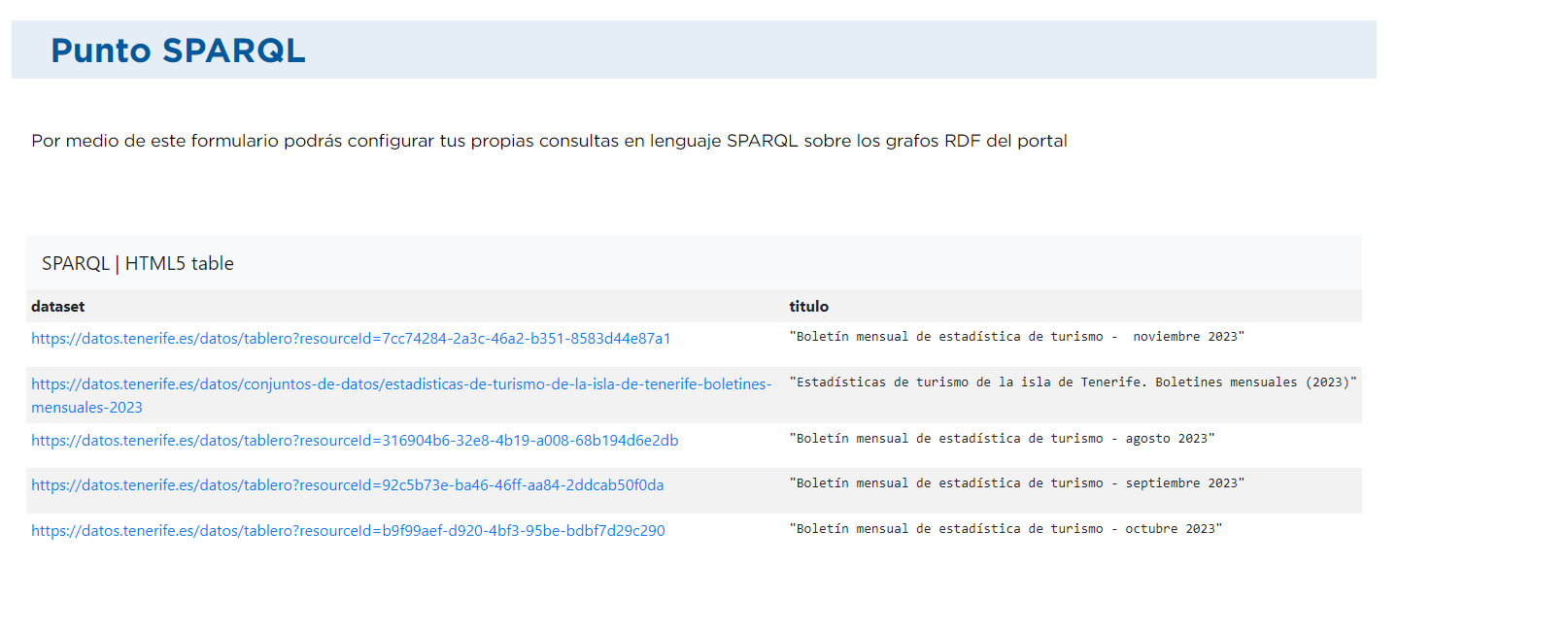
- Filtern nach Textstrings:
In diesem Fall wollen wir die Sätze abrufen, die das Wort "Tourismus" in ihrem Titel (?title) enthalten:
PREFIX dct: <http://purl.org/dc/terms/> PREFIX dcat: <http://www.w3.org/ns/dcat#> SELECT * WHERE { ?dataset dct:title ?title . FILTER (CONTAINS(LCASE(?title), "tourism")) }Das Ergebnis würde wie folgt aussehen:
- Suche nach einem Datensatz oder einer Ressource anhand ihres spezifischen Namens:
Abrufen der URLs der Datensätze oder Ressourcen mit dem Titel "Bushaltestellen".
PREFIX dct: <http://purl.org/dc/terms/> SELECT * WHERE { ?URL dct:title "Bushaltestellen" }
- Filter nach Ressourcentyp
Im Open Data Portal kann ein Datensatz dieselbe Ressource in verschiedenen Formaten (Distributionen) enthalten, so dass wir bei einer Abfrage im SPARQL-Punkt wiederholt Ergebnisse mit demselben Titel erhalten, die wir durch Hinzufügen einer Ressourcentyp-Spalte unterscheiden können.
In der folgenden Abfrage verwenden wir die FILTER-Klausel , um nach den Sätzen mit dem Wort "centres" zu suchen, und wir erhalten ihre Links, Titel und Formate:
PREFIX dct: <http://purl.org/dc/terms/> SELECT WHERE { ?URL dct:title ?title. ?URL dct:format ?format . FILTER (CONTAINS(LCASE(?title), "centres")) } order by asc(?title)
Es gibt auch die Möglichkeit zu filtern, um nur Ressourcen vom Typ GeoJSON zu erhalten.
In diesem Fall gibt es zwei Möglichkeiten der Suche, deren Ergebnis das gleiche wäre:
- Mit FILTER:
PREFIX dct: <http://purl.org/dc/terms/> SELECT * WHERE { ?URL dct:title ?title. ?URL dct:format ?format. FILTER (CONTAINS(LCASE(?title), "Zentren")) FILTER (CONTAINS(LCASE(?format), "geojson")) }) } - Angabe der Textzeichenfolge im Triplett:
PREFIX dct: <http://purl.org/dc/terms/> SELECT * WHERE { ?URL dct:title ?title. ?URL dct:format "GeoJSON" FILTER (CONTAINS(LCASE(?title), "centres")) } }
- Ermittelt Informationen über den Herausgeber der Daten:
Diese Informationen werden in dem Feld dcat:contactPoint gesammelt. In der folgenden Abfrage werden wir die Datensätze abrufen, deren Herausgeber oder Kontaktstelle der Technische Dienst für Landwirtschaft und ländliche Entwicklung (AgroCabildo) ist:
PREFIX dct: <http://purl.org/dc/terms/> PREFIX dcat: <http://www.w3.org/ns/dcat#> SELECT distinct ?URL ?title ?contact_point WHERE { ?URL dct:title ?title. ?URL dcat:contactPoint ?contact_point. FILTER (CONTAINS(LCASE(STR(?contact_point))), "Landwirtschaftlicher technischer Dienst") }) } ORDER BY ASC(?title)
Soviel zur Schulung über den SPARQL Point von datos.tenerife.es, aber wir möchten Sie ermutigen, mehr über unser Portal und alle Möglichkeiten, die es bietet, zu erfahren.