


Automatische Aktualisierung der Daten in Abhängigkeit von ihrer Veröffentlichung im Portal
Über das Portal der offenen Daten des Cabildo de Tenerife können Sie die neuesten Datensätze automatisch oder manuell abrufen oder herunterladen.
Um eine aktualisierte Historie zu erhalten, müssen wir eine Reihe von Schritten befolgen. Je nachdem, wie die Daten im Portal aktualisiert werden, können wir drei Arten von Fällen unterscheiden:
1. Derselbe Datensatz und dieselbe Ressource
Von den drei zu betrachtenden Fällen ist dies der einfachste, da er nur von einer URL abhängt. Sobald die Ressource des Datensatzes gefunden wurde, können wir das Tool unserer Wahl verwenden, um die Daten über die URL der Ressource zu erhalten. Es gibt zwei Methoden, um diese URL zu erhalten.
Die erste und einfachste Methode besteht darin, mit der rechten Maustaste auf die Download-Schaltfläche der Ressource zu klicken und die Option Linkadresse kopieren auszuwählen.
Dies ist zum Beispiel der Fall bei dem Datensatz "Afluencia a Barranco de Masca". Dieser Datensatz hat die Ressource "Afluencia a Barranco de Masca".
Dieser Datensatz verfügt über die Ressource "Einfluss des Zugangs zum Barranco de Masca nach Alter", in der die Anzahl der Personen, die den Barranco besucht haben, erfasst wird.
Wenn wir die oben genannten Schritte durchführen, kopieren wir die URL, die lautet:
Wenn wir diese URL direkt im Browser verwenden, laden wir die Ressource herunter und können sie z. B. auch als Datenquelle in einem Power BI-Bericht verwenden, so dass bei dessen Aktualisierung immer die neuesten verfügbaren Daten abgerufen werden.
In diesem Beispiel haben wir das CSV-Format gewählt, aber wir könnten das Gleiche mit jedem anderen Format tun.
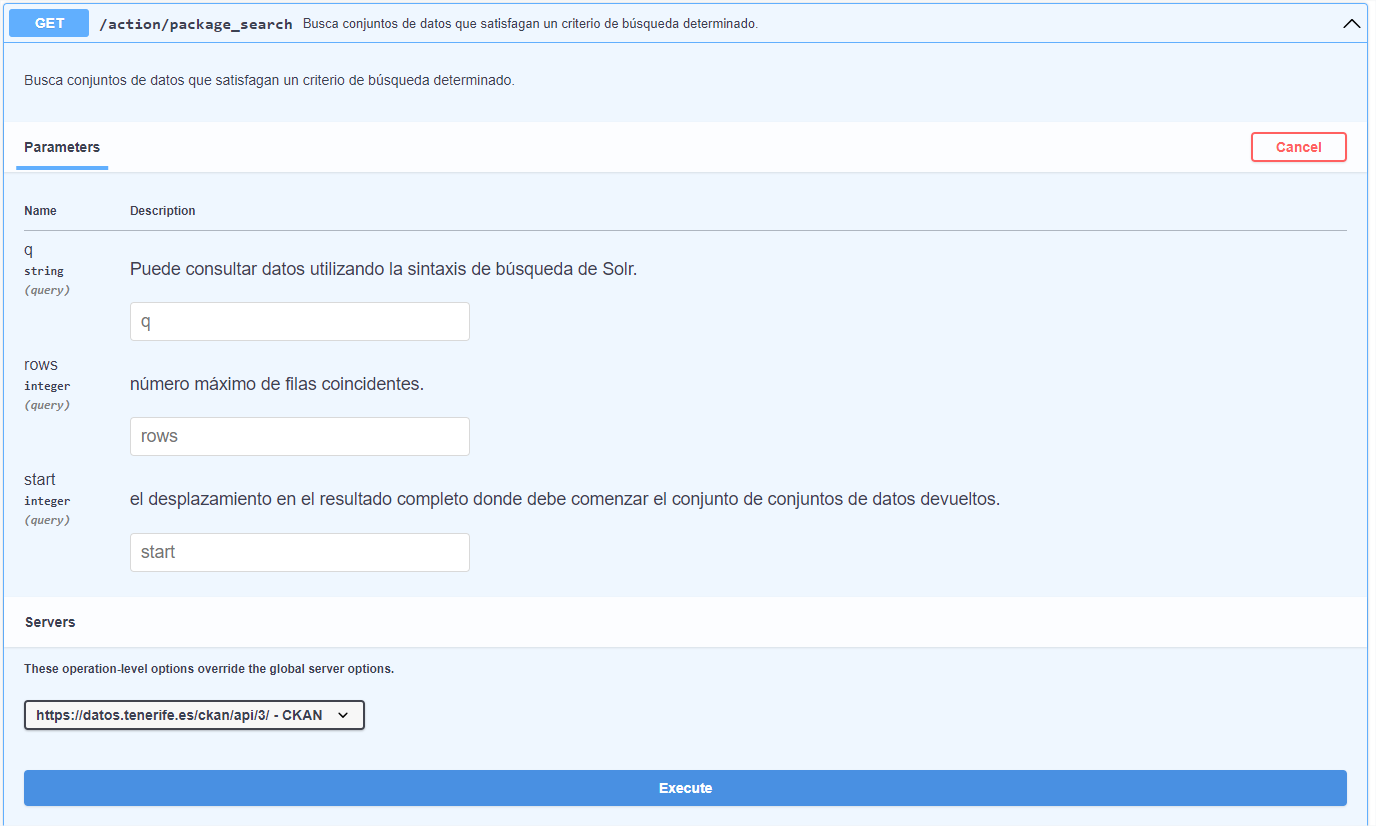
Die zweite Methode, um den für den Download benötigten Link zu erhalten, ist über die Portal-API, die sich im Datenblock befindet.

Von allen angezeigten Endpunkten verwenden wir "package_search" aus dem Abschnitt "Datasets". Dieser Endpunkt sucht nach den Datensätzen, die der Suche entsprechen, und zeigt im JSON-Format die mit dem Datensatz verbundenen Metadaten sowie die für ihn verfügbaren Ressourcen an. Nachdem Sie auf die Schaltfläche "Ausprobieren" geklickt haben, geben Sie den Namen des zu suchenden Datensatzes "Afluencia a Barranco de Masca" im Parameter "q" an und klicken auf die Schaltfläche "Ausführen".
Neben der Überprüfung, dass keine Fehler aufgetreten sind (Code 200), können wir zunächst sehen, wie viele Datensätze unserer Suche entsprechen, in diesem Fall 1.
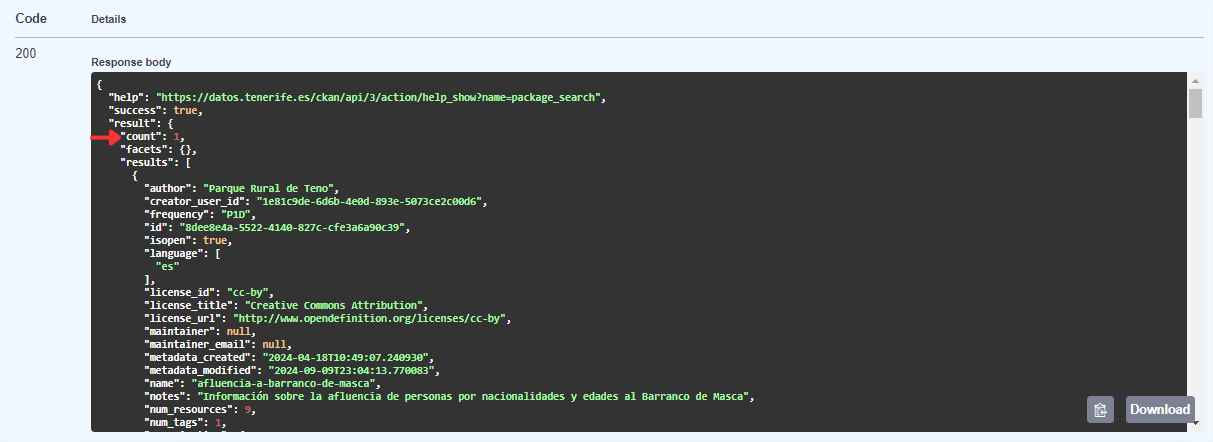
Wenn wir im Ergebnis nach unten blättern, können wir die verschiedenen Metadaten des Datensatzes sehen, z. B. denTitel (title) oder die Beschreibung(notes) und andere.
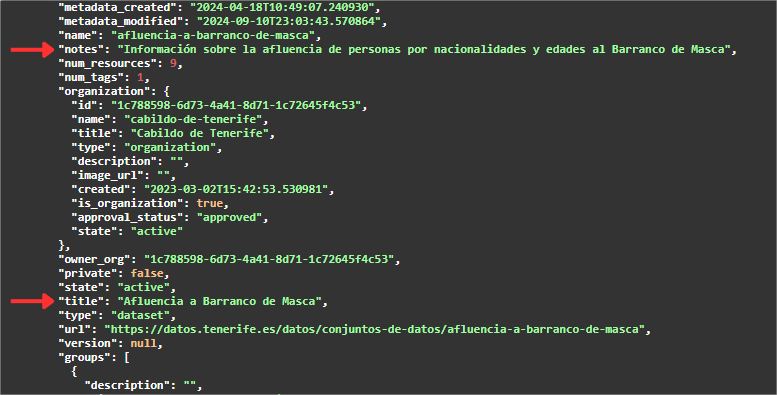
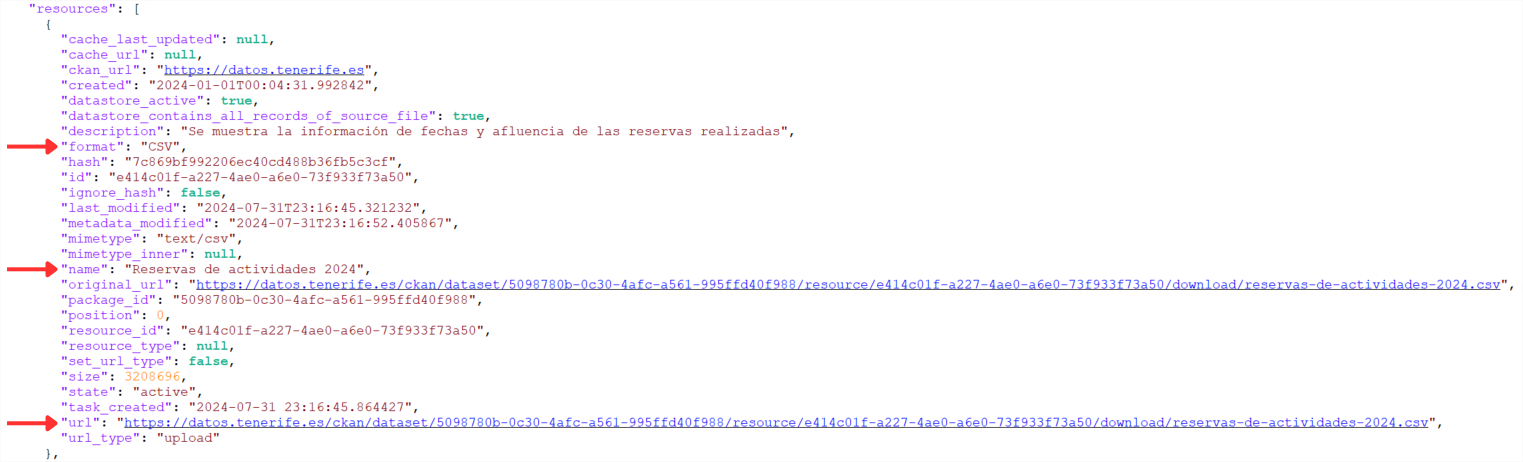
Wenn wir im JSON weiter nach unten scrollen, finden wir ein Array ("resources": [ ]) mit allen für diesen Datensatz verfügbaren Ressourcen. Für eine bessere Visualisierung oder Verwendung kann dieses JSON heruntergeladen werden.
Als nächstes müssen wir nach dem Wert suchen, der mit dem Tag "url" der Ressource verbunden ist, die als Metadaten hat:
- "name": "Einfluss des Zugangs zum Barranco de Masca nach Alter".
- "Format": "CSV".

Als Nächstes müssen wir nach dem Wert suchen, der mit dem Tag "url" der Ressource verbunden ist, die als Metadaten hat:
- "name": "Afluencia de acceso al Barranco de Masca por edad".
- "Format: "CSV".
Auf diese Weise erhalten wir die gleiche URL für die Ressource wie die, die wir mit der ersten Methode erhalten haben. Mit dieser zweiten Methode können wir mit einem einzigen API-Aufruf die URLs mehrerer Ressourcen gleichzeitig abfragen, falls erforderlich.
2. Gleicher Datensatz und verschiedene Ressourcen
Wenn wir im vorherigen Fall von einer einzigen URL abhängig waren und der Abrufvorgang manuell durchgeführt werden konnte (weil nur eine Ressource aktualisiert wird), ist es in diesem Fall interessant, einen Automatisierungsprozess zu haben , der alle Ressourcen abruft, die zur Bildung einer Historie benötigt werden.
Zum Beispiel sind im Datensatz "Reservate für Naturaktivitäten auf Teneriffa" die Ressourcen nach Jahren unterteilt und zeigen die Anzahl der Personen, die eine Aktivität an einem bestimmten Datum ausüben. Wir sollten also alle URLs der Ressourcen (mit der Auswahl des gewünschten Formats) ab dem ersten Jahr, für das es Daten gibt (2016), erhalten.
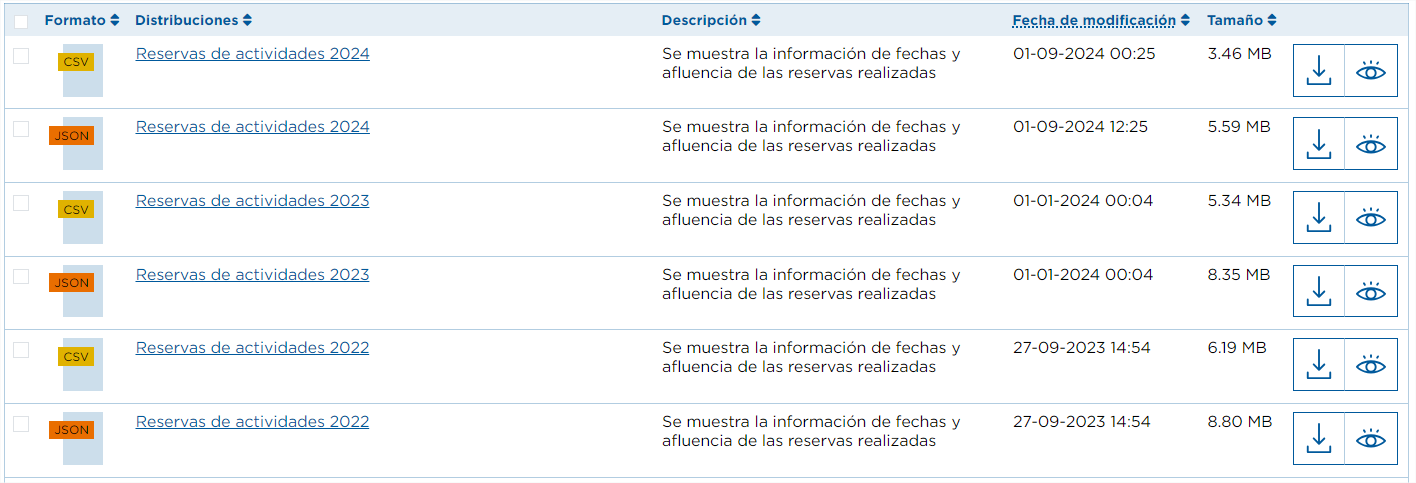
Für den Automatisierungsprozess sollten wir die oben genannten Schritte wiederholen:
- Verwenden Sie den Endpunkt "package_search" im Abschnitt "Datasets" der Portal-API, der sich im Datenblock befindet.
- Geben Sie im Parameter "q" den genauen Namen des zu suchenden Datensatzes in Anführungszeichen an (z. B. "Buchungen von Naturaktivitäten auf Teneriffa") oder ein oder mehrere Wörter, um die Suche durchzuführen (z. B. "Buchungen von Naturaktivitäten").
- Wir überprüfen, ob wir Ergebnisse erhalten, und wenn es mehr als eines gibt, behalten wir die Ergebnisliste, deren Titel mit dem Namen des Datensatzes übereinstimmt.

- Schließlich werden aus dem Array der Ressourcen diejenigen URLs ausgewählt, deren Metadaten das Format "CSV" haben und deren Name "Booking activities" enthält.
Auf diese Weise können wir, wenn die Daten mit den 2025 Reserven veröffentlicht werden, auch automatisch die URL der neuen Ressource durch diesen Prozess sammeln, so dass wir die Daten herunterladen können.
In diesem Fall könnten wir die URLs auch manuell kopieren, denn schließlich befinden sich die Ressourcen im selben Datensatz und wir müssten nur mit der rechten Maustaste klicken, um den Link zu erhalten. Natürlich müssten wir daran denken, jedes Jahr den Datensatz aufzurufen, um die URL der neuen aktualisierten Ressource zu kopieren.
3. Verschiedene Datensätze
In diesem Fall handelt es sich um unterschiedliche Datensätze, die jedoch die gleiche" Ressourcenbeziehung haben. Auch in diesem Fall ist die Automatisierung nicht nur interessant, sondern auch empfehlenswert. Wenn wir uns beispielsweise für die Analyse der täglichen Wetterdaten aller Stationen auf Teneriffa interessieren, verfügt das Portal derzeit über Daten für 62 Stationen, jede mit jährlichen Ressourcen bis 2024, sowohl im CSV- als auch im JSON-Format. Das bedeutet Hunderte von Ressourcen, deren URL gesammelt werden müsste, und jedes Jahr kommen weitere hinzu.
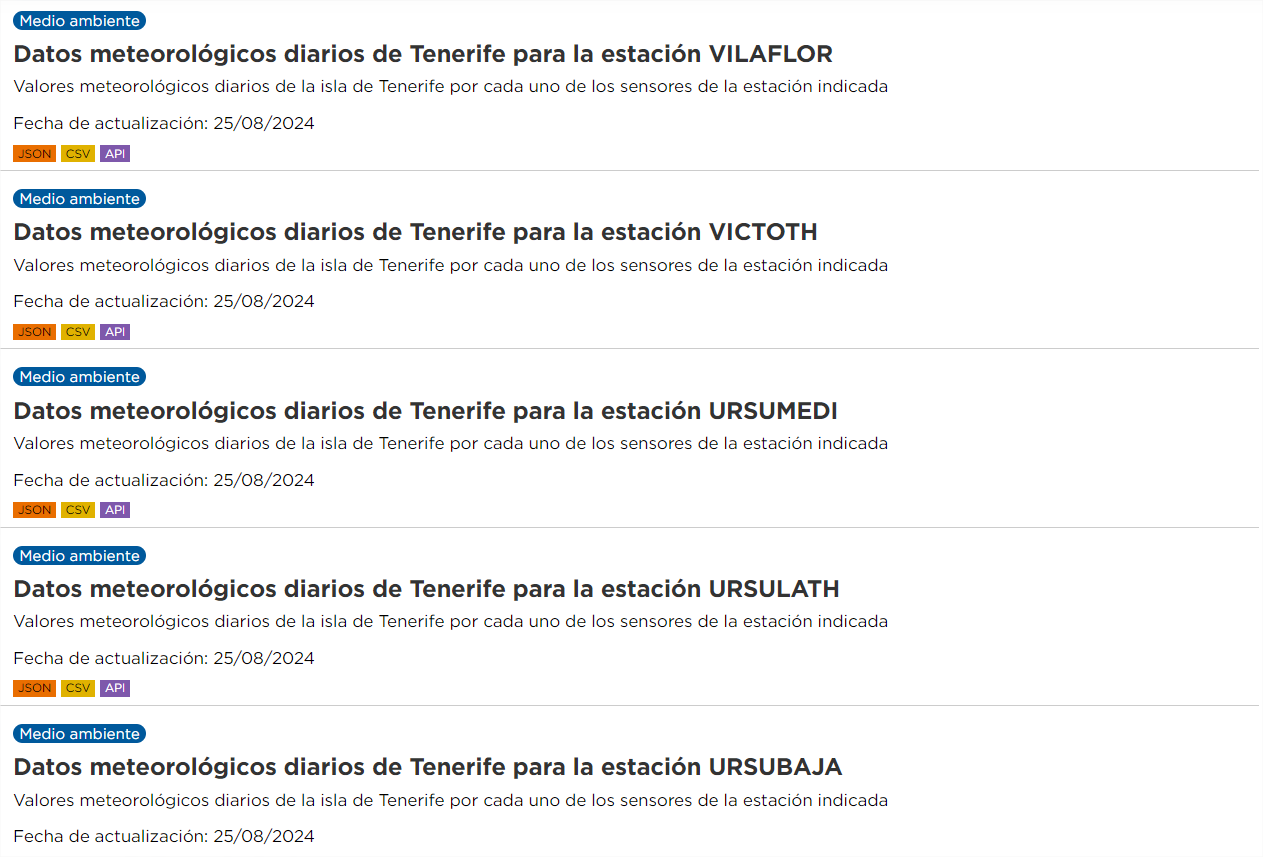
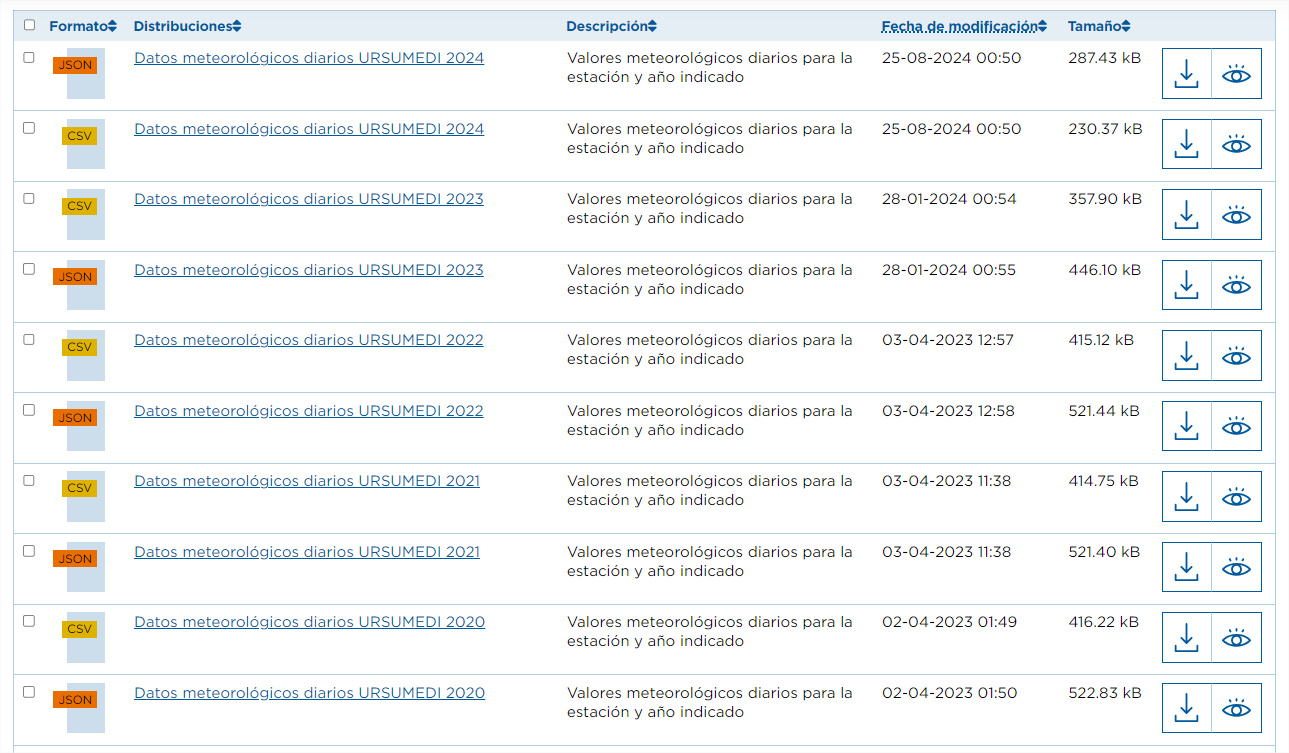
Die Schritte, die in diesem Fall auszuführen sind, sind die gleichen wie im vorherigen Fall, außer dass der Parameter "q" einen generischen Wert enthalten muss, z. B. "Tägliche Wetterdaten" (denken Sie daran, ihn in Anführungszeichen zu setzen).
Dieser Endpunkt ist auf 10 Ergebnisse bzw. Datensätze beschränkt, so dass wir diesen Endpunkt starten müssen, indem wir den Parameter rows so ändern, dass er mehr Sätze zurückgibt.
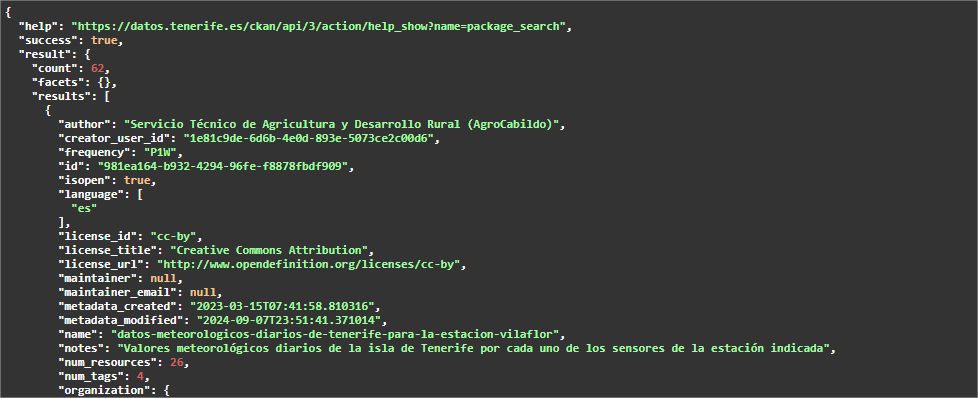
Da die erwartete Anzahl der Ergebnisse 62 ist, können wir in rows z. B. 100 angeben. Da swagger als API-Dokumentation verwendet wird und das abzurufende JSON recht groß ist, was zu Ladeproblemen auf der Portalseite führen kann, ist es ratsam, die Abfrage direkt in einem anderen Browser-Tab zu starten. Die auszuführende URL wäre:
https://datos.tenerife.es/ckan/api/3/action/package_search?q=%22Datos%20meteorol%C3%B3gicos%20diarios%22&rows=100
Wie im vorherigen Fall würden wir die URLs der Ressourcen filtern, deren Name "Tägliche Wetterdaten" enthält und deren Format "CSV" ist.
Weitere Informationen über die Verwendung der API des offenen Datenportals des Cabildo finden Sie im Artikel "API des offenen Datenportals: Automatisierter Datenverbrauch". Ein Video über die Verwendung der API des Portals für offene Daten ist ebenfalls verfügbar.