


The Cabildo de Tenerife's Open Data portal includes a SPARQL Point, which allows queries to search for sets containing a specific word or specific resources.
SPARQL(SPARQL Protocol and RDF Query Language) is a query language designed to retrieve and manipulate data stored in RDF (Resource Description Framework) format, a standard for representing information on the semantic web.
The tool used to store and query this data is Virtuoso, which stores the data in the form of RDF graphs formed by subject-predicate-object triples, representing the relationships between entities and the values they have for certain properties.
In the following, we will explain in more detail what it consists of and how it is used.
Access to the SPARQL Point
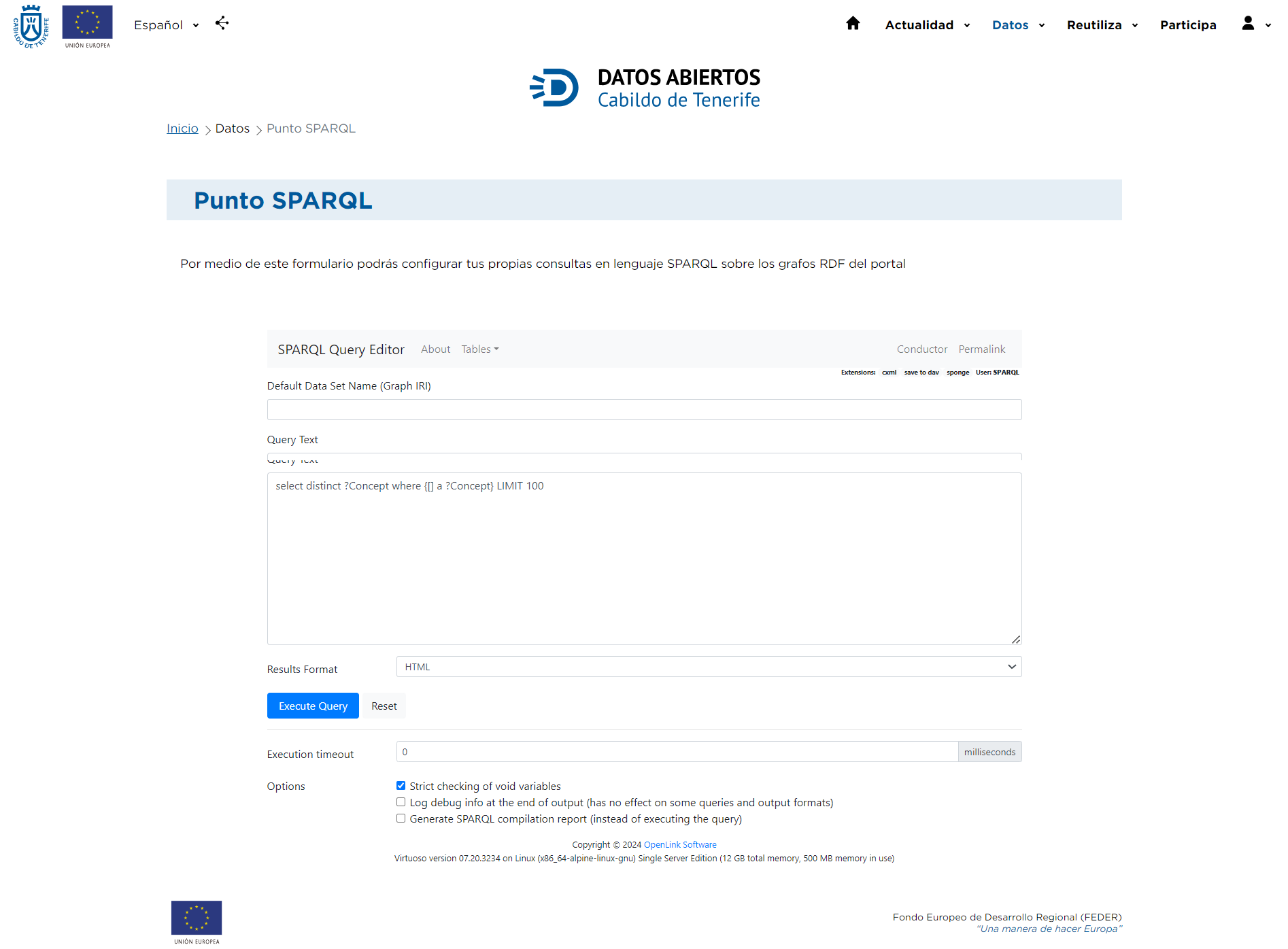
To access the SPARQL Point of the portal datos.tenerife.es you have to deploy the Data tab, located at the top left of the Home page.

After accessing the SPARQL Point, a screen will appear with different options that will allow you to narrow down your search.
With SPARQL it is possible to create complex queries that relate elements to each other by taking advantage of the RDF network structure. The SPARQL syntax is similar to SQL queries, since it consists of SELECT, WHERE, FILTER, ORDER BY, etc. operators.
It incorporates a series of prefixes(PREFIX) that serve to abbreviate long URIs(Uniform Resource Identifier) and make queries more readable and compact.
In the Query Text box you can enter the desired queries, following the indications explained in the following points, and execute them by clicking on the Execute Query button. Once the query has been executed, the result will be displayed in a new tab. To re-launch another query either use the browser's back button or click on the SPARQL | HTML5 table options. Finally, by clicking on the Reset button we delete the entered query and see the example query.
On the other hand, in the SPARQL Point of the Cabildo's Open Data portal you can choose the format in which to obtain the results of the query using the different values of the drop-down "Results format": Auto, HTML, SpreadSheet, XML, JSON, Javascript, Turtle, RDF/XML, N-Triples, CSV and TSV.
In addition, at the bottom of the page you can choose between three different options:
- Strict checking of void variables: When you run a SPARQL query, you can use variables that do not have a value assigned to them (void variables). This option indicates whether you want the system to perform a strict check of these variables to ensure that they are not used incorrectly or inappropriately in your query. If you enable this option, the system may throw an error if it finds empty variables that should not be there, according to the query rules.
- Log debug info at the end of output: This option suggests that, when enabled, debugging details will be logged at the end of the query result. Debugging information usually includes internal details of the query execution process and can be useful for identifying problems or understanding how the query is processed. Note, however, that this option may not be effective for some queries or specific output formats.
- Generate SPARQL compilation report: Instead of executing the SPARQL query this option indicates that a report will be generated showing how the query would be compiled or processed internally. This report could be useful to understand the performance or efficiency of the query without having to fully execute it. It may help to identify possible optimizations before the actual execution.
Use SPARQL Point
To understand SPARQL it is best to use an example and explain it part by part.
Suppose we have a series of RDF graphs describing information or metadata about published datasets and resources, having information about the title, description, publisher, format, etc.
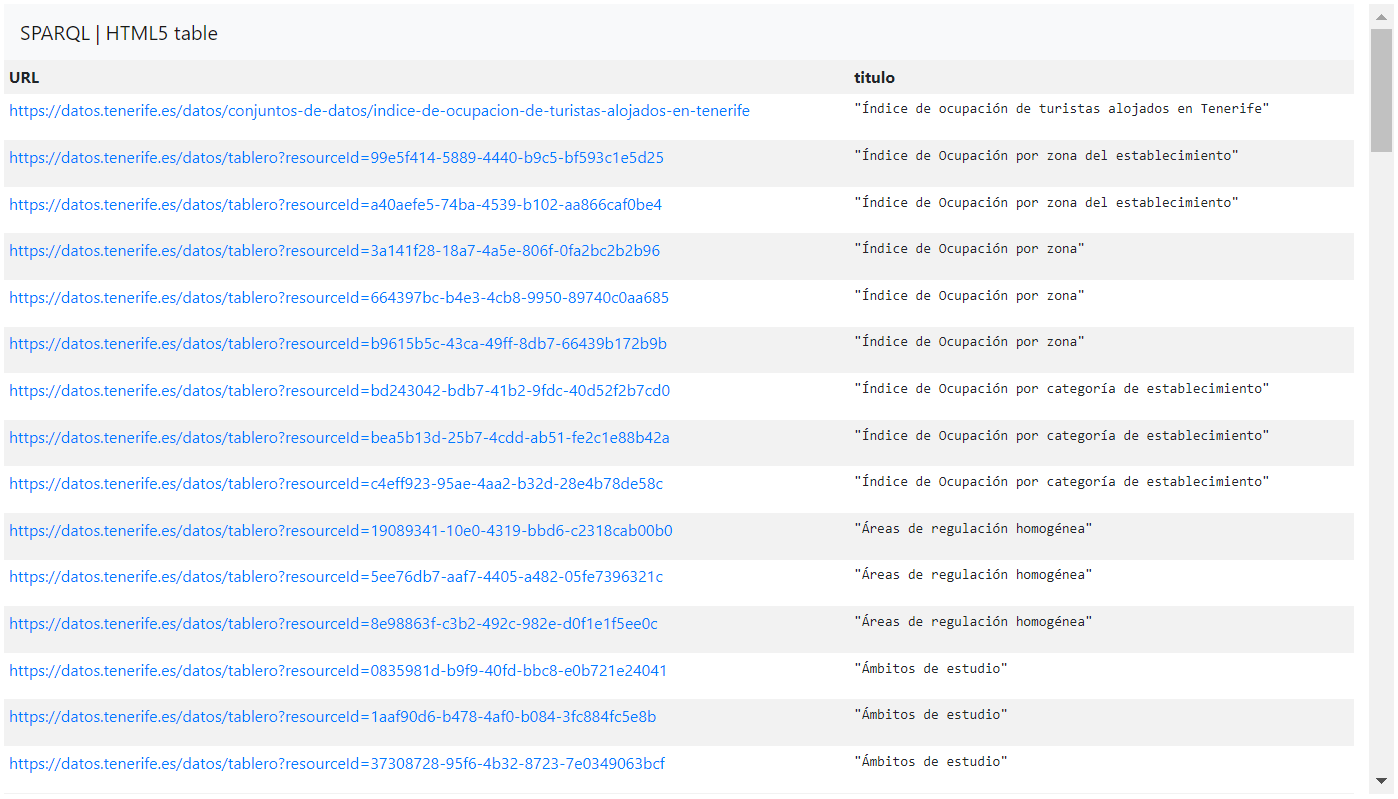
In this case, we would perform a simple SPARQL query to get the first hundred datasets or resources and their links sorted by their title:
PREFIX dct: <http://purl.org/dc/terms/> Select distinct ?URL ?title where { ?URL dct:title ?title } order by desc(?title) LIMIT 100.The explanation of the code is as follows:
- PREFIX: This prefix assigns the alias"dct" to the base URI " http://purl.org/dc/terms/". It is used to abbreviate the URIs in the query.
- SELECT: Specifies the variables we want to retrieve in the query results. In this case, we want to get the first hundred datasets or resources with their URLs. The distinct clause ensures that only unique results are displayed (no repeats).
- WHERE: Defines the RDF triple pattern to be searched in the network:
- ?URL dct:title ?title: Here we are looking for triples where some set has a title. The variable ?title will be used to represent those titles.
We can also get any other kind of information that we have in the RDF, description, publisher...
In this way, the SPARQL query would give us results like the following:
Referring to the Cabildo de Tenerife Open Data portal we will show a series of examples of SPARQL queries to retrieve information about published data.
In this case, Virtuoso relies on the portal's metadata catalog provided at https://datos.tenerife.es/es/datos/tablero?resourceId=17e64992-df93-4c8d-b9a5-5c860b1e978c to obtain the metadata of the published sets and resources to create the RDF graphs.
Examples
In the following, we will explain, with different examples, the different types of search that can be performed in the portal.
1. Obtain the name and link of all the datasets and resources of the portal:
In this way you can obtain the name and link (URL) of all the datasets and their resources (distributions) published in the portal .
PREFIX dct: <http://purl.org/dc/terms/> SELECT distinct ?name ?URL WHERE{ ?URL dct:title ?name } 
2. Filtering by text strings:
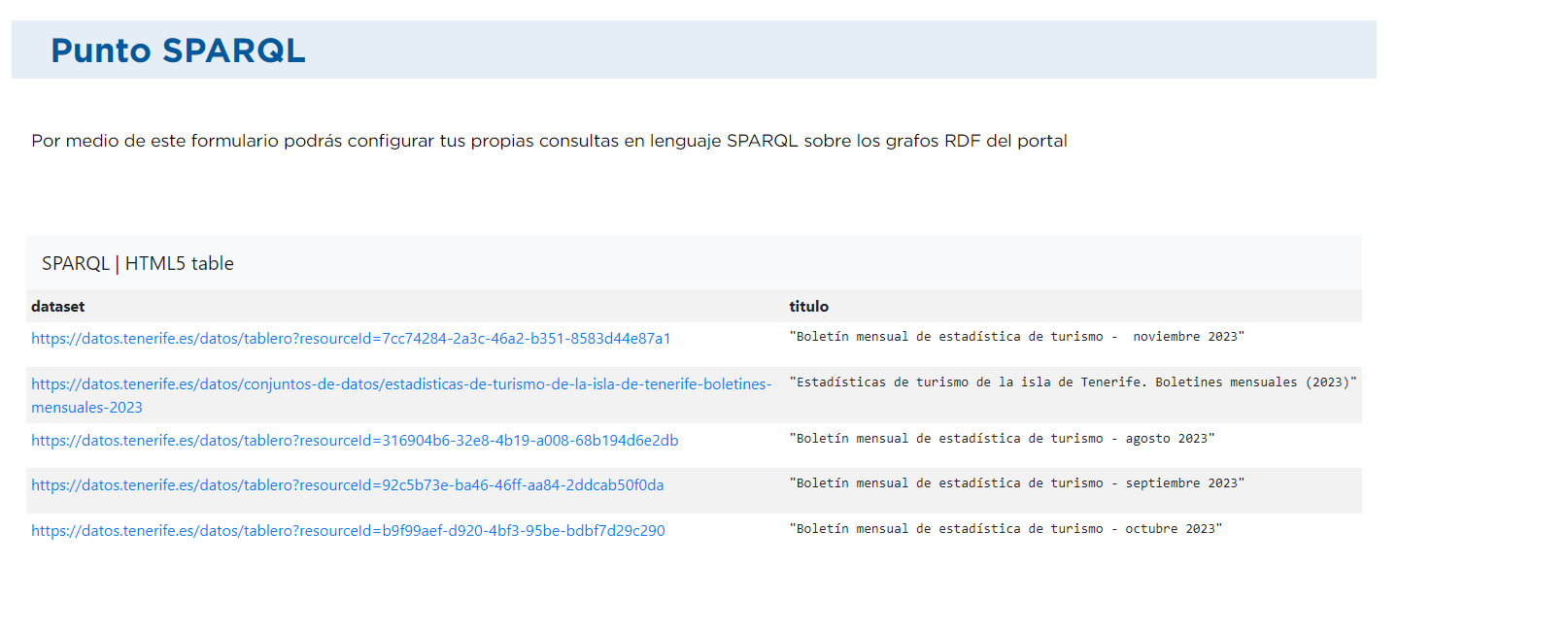
In this case we want to retrieve those sets that have the word "tourism" in their title (?title):
PREFIX dct: <http://purl.org/dc/terms/> PREFIX dcat: <http://www.w3.org/ns/dcat#> SELECT * WHERE { ?dataset dct:title ?title . FILTER (CONTAINS(LCASE(?title), "tourism")) }The result would be this:
3. Search for a dataset or resource by its specific name:
Get the URLs of the datasets or resources with title "Bus stops".
PREFIX dct: <http://purl.org/dc/terms/> SELECT * WHERE { ?URL dct:title "Bus stops" }
4. Filter by resource type
In the open data portal a dataset can have the same resource in several formats (distributions), so when querying in the SPARQL point we will get repeated results with the same title, which we can differentiate by adding a resource type column.
In the following query we will search by means of the FILTER clause for those sets that have the word "centers" and we will obtain their links, titles and formats:
PREFIX dct: <http://purl.org/dc/terms/> SELECT WHERE { ?URL dct:title ?title. ?URL dct:format ?format . FILTER (CONTAINS(LCASE(?title), "centers")) } order by asc(?title)
There is also the possibility of filtering to get only GeoJSON type resources.
In this case, there are two ways of searching, whose result would be the same:
Using FILTER:
PREFIX dct: <http://purl.org/dc/terms/> SELECT * WHERE { ?URL dct:title ?title. ?URL dct:format ?format. FILTER (CONTAINS(LCASE(?title), "centers")) FILTER (CONTAINS(LCASE(?format), "geojson")) })Indicating the text string in the triplet:
PREFIX dct: <http://purl.org/dc/terms/> SELECT * WHERE { ?URL dct:title ?title. ?URL dct:format "GeoJSON" FILTER (CONTAINS(LCASE(?title), "centers")) } 5. Get information about the publisher of the data:
5. Get information about the publisher of the data:
This information is collected in the dcat:contactPoint field. In the following query we are going to retrieve those sets whose publisher or contact point is the Technical Service of Agriculture and Rural Development (AgroCabildo):
PREFIX dct: <http://purl.org/dc/terms/> PREFIX dcat: <http://www.w3.org/ns/dcat#> SELECT distinct ?URL ?title ?contact_point WHERE { ?URL dct:title ?title. ?URL dcat:contactPoint ?contact_point. FILTER (CONTAINS(LCASE(STR(?contact_point)), "agricultural technical service") }) } ORDER BY ASC(?title)
So much for the training on the SPARQL Point of datos.tenerife.es, but we encourage you to continue learning more about our portal and all the possibilities it offers.