


Point SPARQL : qu'est-ce que c'est et comment l'utiliser
Le portail Open Data du Cabildo de Tenerife comprend un point SPARQL, qui permet d'effectuer des requêtes pour rechercher des ensembles contenant un mot spécifique ou des ressources spécifiques.
SPARQL(SPARQL Protocol and RDF Query Language) est un langage de requête conçu pour récupérer et manipuler des données stockées au format RDF (Resource Description Framework), un standard de représentation de l'information sur le web sémantique.
L'outil utilisé pour stocker et interroger ces données est Virtuoso, qui stocke les données sous la forme de graphes RDF formés par des triplets sujet-prédicat-objet, qui représentent les relations entre les entités et les valeurs qu'elles ont pour certaines propriétés.
Dans ce qui suit, nous expliquerons plus en détail ce qu'il est et comment il est utilisé.
ACCÈS AU POINT SPARQL
Pour accéder au point SPARQL du portail datos.tenerife.es, il faut déployer l'onglet Données, situé dans la partie supérieure gauche de la page d'accueil.

Après avoir accédé au point SPARQL, un écran apparaîtra avec différentes options qui vous permettront d'affiner votre recherche.
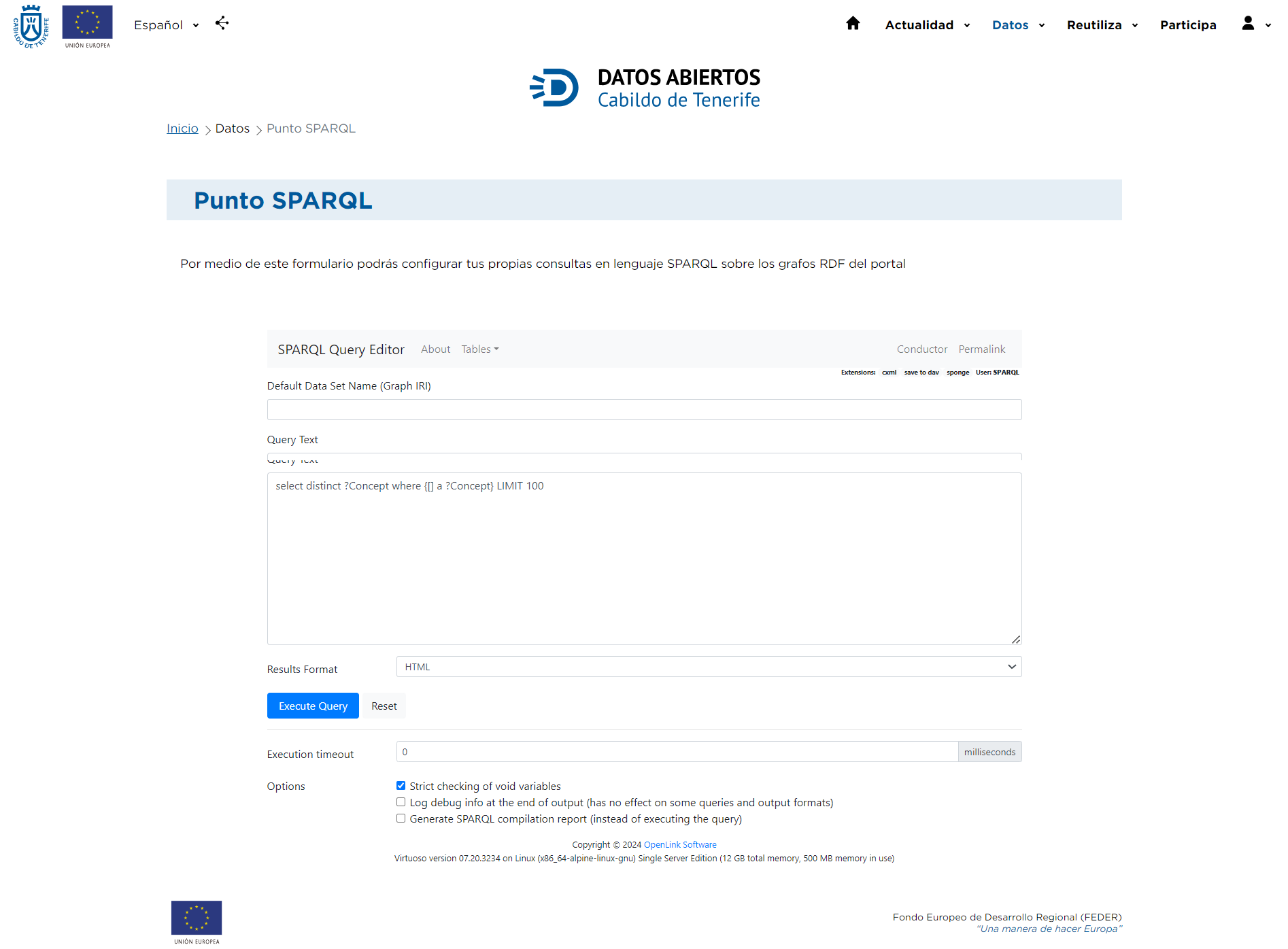
Avec SPARQL, il est possible de créer des requêtes complexes qui relient des éléments entre eux en tirant parti de la structure du graphe RDF. La syntaxe SPARQL est similaire à celle des requêtes SQL, puisqu'elle se compose des opérateurs SELECT, WHERE, FILTER, ORDER BY, etc.
Elle comprend une série de préfixes(PREFIX) qui servent à abréger les longs URI(Uniform Resource Identifier) et à rendre les requêtes plus lisibles et plus compactes.
Dans le champ Texte de la requête, vous pouvez saisir les requêtes souhaitées, en suivant les indications expliquées dans les points suivants, et les exécuter en cliquant sur le bouton Exécuter la requête. Une fois la requête exécutée, le résultat sera affiché dans un nouvel onglet. Pour relancer une autre requête, il faut soit utiliser le bouton retour du navigateur, soit cliquer sur les options du tableau SPARQL | HTML5. Enfin, en cliquant sur le bouton Réinitialiser, nous supprimons la requête saisie et voyons l'exemple de requête.
D'autre part, dans le Point SPARQL du portail Open Data du Cabildo, vous pouvez choisir le format dans lequel vous souhaitez obtenir les résultats de la requête en utilisant les différentes valeurs du menu déroulant "Format des résultats" : Auto, HTML, SpreadSheet, XML, JSON, Javascript, Turtle, RDF/XML, N-Triples, CSV et TSV.
En outre, au bas de la page, vous pouvez choisir entre trois options différentes :
- Vérification stricte des variables nulles: Lorsque vous exécutez une requête SPARQL, vous pouvez utiliser des variables auxquelles aucune valeur n'a été attribuée (void variables). Cette option indique si vous souhaitez que le système effectue un contrôle strict de ces variables afin de s'assurer qu'elles ne sont pas utilisées de manière incorrecte ou inappropriée dans votre requête. Si vous activez cette option, le système peut générer une erreur s'il trouve des variables vides qui ne devraient pas se trouver là, selon les règles de la requête.
- Enregistrer les informations de débogage à la fin de la sortie : Cette option suggère que, lorsqu'elle est activée, les détails de débogage seront enregistrés à la fin de la sortie de la requête. Les informations de débogage comprennent généralement des détails internes du processus d'exécution de la requête et peuvent être utiles pour identifier les problèmes ou comprendre comment la requête est traitée. Notez cependant que cette option peut ne pas être efficace pour certaines requêtes ou certains formats de sortie.
- Générer un rapport de compilation SPARQL: Au lieu d'exécuter la requête SPARQL, cette option indique qu'un rapport sera généré, montrant comment la requête serait compilée ou traitée en interne. Ce rapport peut être utile pour comprendre les performances ou l'efficacité de la requête sans avoir à l'exécuter complètement. Il peut aider à identifier les optimisations possibles avant l'exécution réelle.
UTILISER SPARQL POINT
Pour comprendre SPARQL, il est préférable d'utiliser un exemple et de l'expliquer partie par partie.
Supposons que nous disposions d'une série de graphes RDF décrivant des informations ou des métadonnées sur des ensembles de données et des ressources publiés, avec des informations sur le titre, la description, l'éditeur, le format, etc.
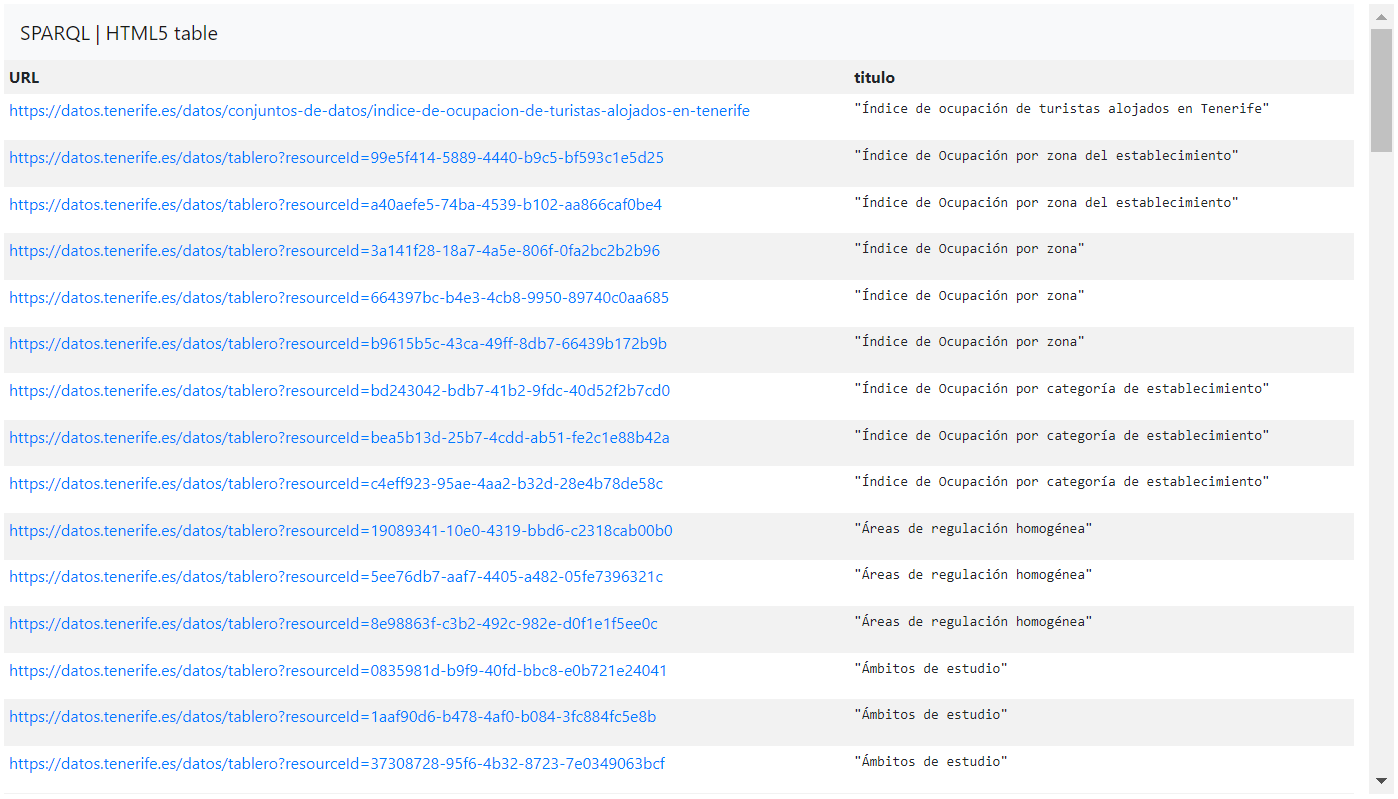
Dans ce cas, nous effectuerions une simple requête SPARQL pour obtenir les cent premiers ensembles de données ou ressources et leurs liens, triés par titre :
PREFIX dct : <http://purl.org/dc/terms/> Select distinct ?URL ?title where { ?URL dct:title ?title } order by desc(?title) LIMIT 100L'explication du code est la suivante :
- PREFIX : Ce préfixe attribue l'alias"dct" à l'URI de base " http://purl.org/dc/terms/". Il est utilisé pour abréger les URI dans la requête.
- SELECT : Spécifie les variables que nous voulons récupérer dans les résultats de la requête. Dans le cas présent, nous voulons obtenir les cent premiers ensembles de données ou ressources avec leur URL. La clause distincte permet de s'assurer que seuls les résultats uniques sont affichés (pas de répétitions).
- WHERE : définit le modèle triple RDF à rechercher dans le réseau :
- ?URL dct:title ?title : Ici, nous recherchons des triples où un ensemble a un titre. La variable ?title sera utilisée pour représenter ces titres.
Nous pouvons également obtenir tout autre type d'information que nous avons dans le RDF, description, éditeur...
De cette manière, la requête SPARQL nous donnerait des résultats comme les suivants :
En nous référant au portail de données ouvertes du Cabildo de Tenerife, nous montrerons une série d'exemples de requêtes SPARQL pour récupérer des informations sur les données publiées.
Dans ce cas, Virtuoso s'appuie sur le catalogue de métadonnées du portail fourni à l'adresse https://datos.tenerife.es/es/datos/tablero?resourceId=17e64992-df93-4c8d-b9a5-5c860b1e978c pour obtenir les métadonnées des ensembles et ressources publiés afin de créer les graphes RDF.
EXEMPLES
Dans ce qui suit, nous allons expliquer, à l'aide de différents exemples, les différents types de recherche qui peuvent être effectués dans le portail.
- Obtenir le nom et le lien de tous les ensembles de données et de toutes les ressources du portail:De cette façon,vous pouvez obtenir le nom et le lien (URL) de tous les ensembles de données et de leurs ressources (distributions) publiés dans le portail .
PREFIX dct : <http://purl.org/dc/terms/> SELECT distinct ?name ?name ?URL WHERE{ ?URL dct:title ?name }
- Filtrage par chaînes de texte :
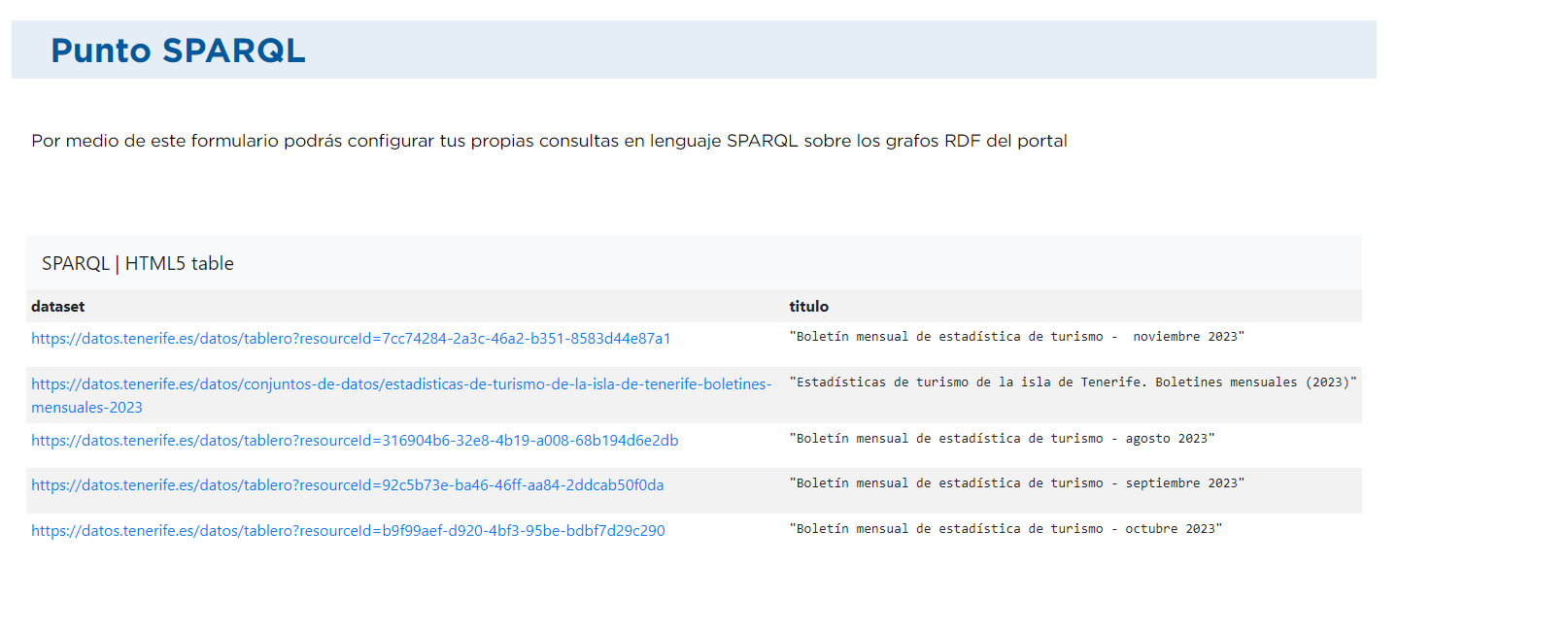
Dans ce cas, nous voulons extraire les ensembles dont le titre contient le mot "tourisme" (?title) :
PREFIX dct : <http://purl.org/dc/terms/> PREFIX dcat : <http://www.w3.org/ns/dcat#> SELECT * WHERE { ?dataset dct:title ?title . FILTER (CONTAINS(LCASE(?title), "tourism")) }Le résultat ressemblerait à ceci :
- Recherche d'un jeu de données ou d'une ressource par son nom spécifique :
Obtenir les URL des jeux de données ou des ressources dont le titre est "Arrêts de bus".
PREFIX dct : <http://purl.org/dc/terms/> SELECT * WHERE { ?URL dct:title "Arrêts de bus" }
- Filtrer par type de ressource
Dans le portail de données ouvertes, un jeu de données peut contenir la même ressource sous plusieurs formats (distributions). Par conséquent, lors de l'interrogation du point SPARQL, nous obtiendrons des résultats répétés avec le même titre, que nous pouvons différencier en ajoutant une colonne de type de ressource.
Dans la requête suivante, nous utiliserons la clause FILTER pour rechercher les ensembles contenant le mot "centres" et nous obtiendrons leurs liens, titres et formats :
PREFIX dct : <http://purl.org/dc/terms/> SELECT WHERE { ?URL dct:title ?title. ?URL dct:format ?format . FILTER (CONTAINS(LCASE(?title), "centres")) } order by asc(?title)
Il est également possible de filtrer pour n'obtenir que les ressources de type GeoJSON.
Dans ce cas, il y a deux façons de chercher, dont le résultat serait le même :
- En utilisant FILTER :
PREFIX dct : <http://purl.org/dc/terms/> SELECT * WHERE { ?URL dct:title ?title. ?URL dct:format ?format. FILTRE (CONTAINS(LCASE(?title), "centres")) FILTRE (CONTAINS(LCASE(?format), "geojson")) }) } - Indique la chaîne de texte dans le triplet :
PREFIX dct : <http://purl.org/dc/terms/> SELECT * WHERE { ?URL dct:title ?title. ?URL dct:format "GeoJSON" FILTER (CONTAINS(LCASE(?title), "centres")) } }
- Obtenir des informations sur l'éditeur des données :
Cette information est collectée dans le champ dcat:contactPoint . Dans la requête suivante, nous allons récupérer les ensembles dont l'éditeur ou le point de contact est le Service technique de l'agriculture et du développement rural (AgroCabildo) :
PREFIX dct : <http://purl.org/dc/terms/> PREFIX dcat : <http://www.w3.org/ns/dcat#> SELECT distinct ?URL ?title ?contact_point WHERE { ?URL dct:title ?title. ?URL dcat:contactPoint ?contact_point. FILTER (CONTAINS(LCASE(STR(?contact_point)), "agriculture technical service") }) } ORDER BY ASC(?title)
Voilà pour la formation sur le point SPARQL de datos.tenerife.es, mais nous vous encourageons à continuer à en apprendre davantage sur notre portail et toutes les possibilités qu'il offre.