


Mise à jour automatique des données en fonction de leur publication sur le portail
Le portail de données ouvertes du Cabildo de Tenerife vous permet de consulter ou de télécharger automatiquement ou manuellement les ensembles de données les plus récents.
Pour disposer d'un historique actualisé , il faut suivre une série d'étapes. Selon la manière dont les données sont mises à jour dans le portail, on peut distinguer trois types de cas :
1. Même jeu de données et même ressource
Des trois cas à considérer, celui-ci est le plus simple, car il ne dépend que d'une URL. Une fois l'ensemble de données localisé, nous pouvons utiliser l'outil de notre choix pour obtenir les données par l'intermédiaire de l'URL de la ressource. Deux méthodes peuvent être utilisées pour obtenir cette URL.
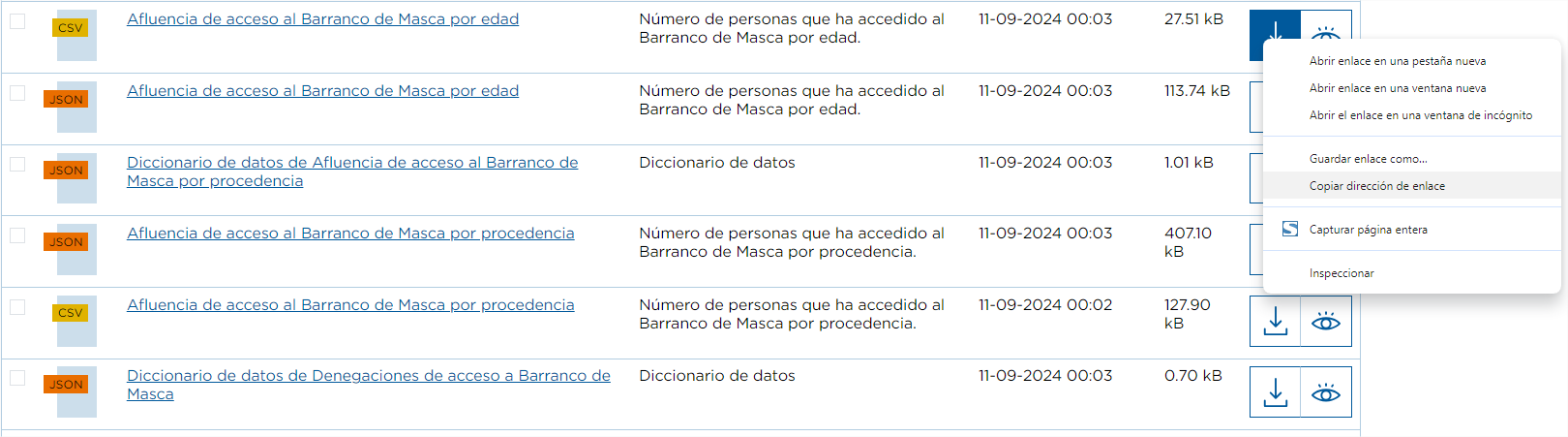
La première et la plus simple consiste à faire un clic droit sur le bouton de téléchargement de la ressource et à sélectionner l'option Copier l'adresse du lien.
C'est par exemple le cas de l'ensemble de données "Afluencia a Barranco de Masca". Ce jeu de données possède la ressource "Afluencia a Barranco de Masca".
Ce jeu de données possède la ressource "Influence de l'accès au Barranco de Masca par âge" où est enregistré le nombre de personnes ayant accédé au Barranco.
En effectuant les étapes ci-dessus, nous copierons son URL, qui est :
Si nous utilisons cette URL directement dans le navigateur, nous téléchargerons la ressource et, par exemple, nous pourrons également l'utiliser comme source de données dans un rapport Power BI, de sorte que lorsqu'il est mis à jour, il récupère toujours les dernières données disponibles.
Dans cet exemple, nous avons choisi le format CSV, mais nous pourrions faire de même avec n'importe quel autre type de format.
La deuxième méthode pour obtenir le lien nécessaire au téléchargement consiste à utiliser l'API du portail, qui se trouve dans le bloc de données.

Parmi tous les points de terminaison qui apparaissent, nous utilisons "package_search" de la section "Datasets". Ce point d'accès recherche les ensembles de données qui répondent à la recherche et affiche au format JSON les métadonnées associées à l'ensemble de données, ainsi que les ressources disponibles. Après avoir cliqué sur le bouton "Try it out", nous indiquons le nom de l'ensemble de données à rechercher "Afluencia a Barranco de Masca" dans le paramètre "q" et nous cliquons sur le bouton "Execute".
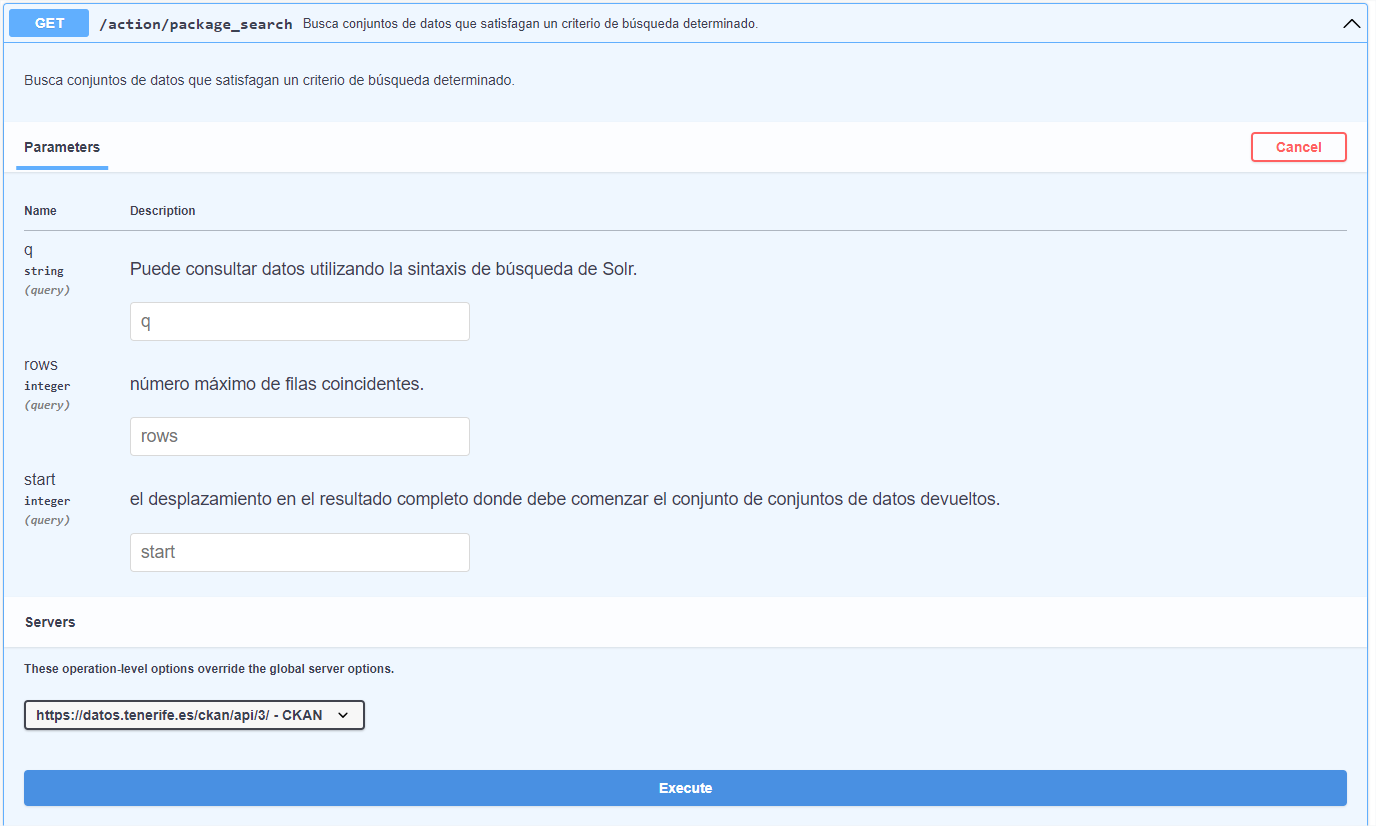
Tout d'abord, en plus de vérifier qu'il n'y a pas eu d'erreurs (code 200), nous pouvons voir combien d'ensembles de données satisfont notre recherche, dans ce cas 1.
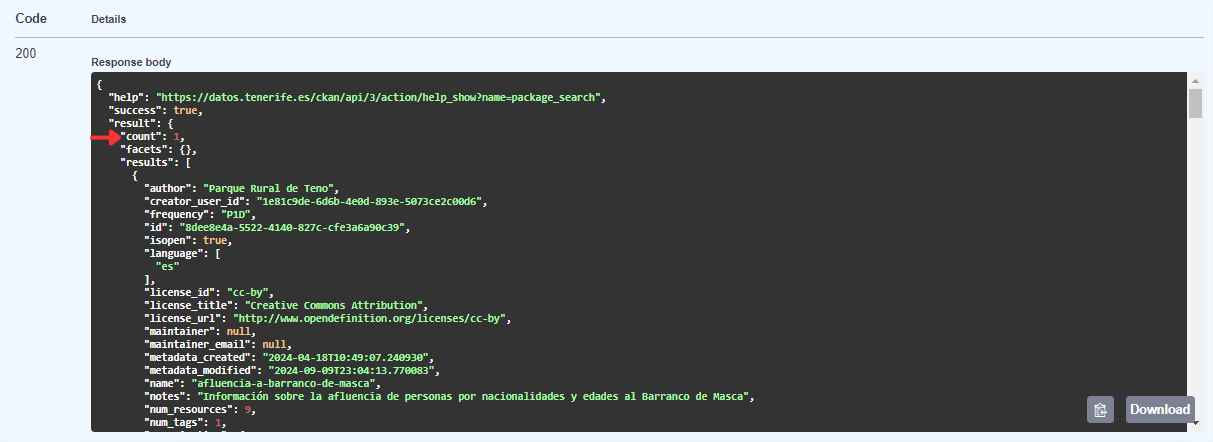
Au fur et à mesure que nous descendons dans le résultat, nous pouvons voir les différentes métadonnées de l'ensemble, par exemple sontitre (title) ou sa description(notes), entre autres.
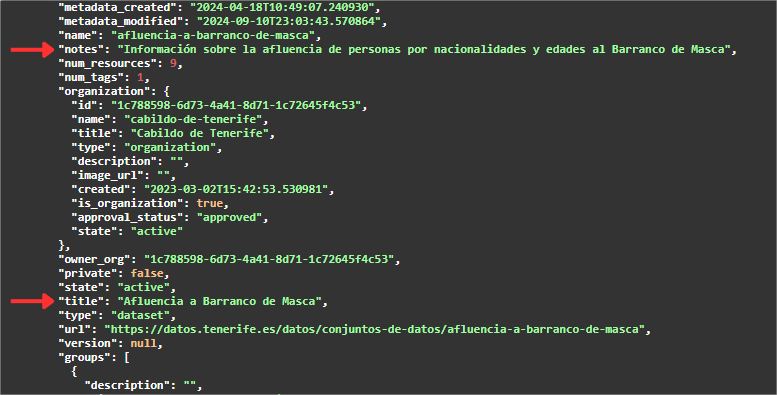
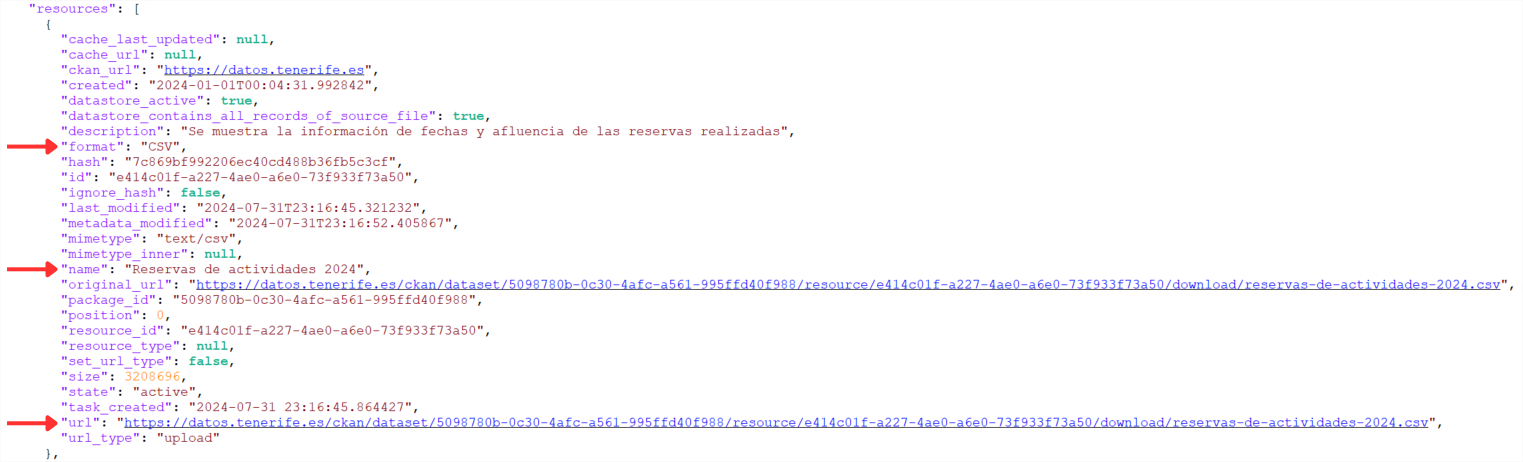
Si nous continuons à faire défiler le JSON, nous trouverons un tableau ("resources" : [ ]) avec toutes les ressources disponibles pour cet ensemble de données. Pour une meilleure visualisation ou utilisation, il est possible de télécharger ce JSON.
Ensuite, il faut chercher la valeur associée à la balise "url" de la ressource qui a comme métadonnées :
- "name" : "Influence de l'accès au Barranco de Masca par âge".
- "format" : "CSV".

Ensuite, nous devons rechercher la valeur associée à la balise "url" de la ressource qui a comme métadonnées :
- "name" : "Afluencia de acceso al Barranco de Masca por edad".
- "format : "CSV".
Nous obtenons ainsi la même URL pour la ressource que celle obtenue avec la première méthode. Avec cette deuxième méthode, nous pourrions trouver en un seul appel API les URL de plusieurs ressources en même temps, si nécessaire.
2. Même ensemble de données et ressources différentes
Si, dans le cas précédent, nous dépendions d'une seule URL et que le processus de récupération pouvait être effectué manuellement (parce qu'une seule ressource est mise à jour), dans ce cas, il est intéressant d'avoir un processus d'automatisation qui récupère toutes les ressources nécessaires pour former un historique .
Par exemple, dans l'ensemble de données "Réserves d'activités de nature à Tenerife", les ressources sont divisées par années, montrant le nombre de personnes pratiquant une activité à une date donnée. Nous devrions donc obtenir toutes les URL des ressources (en choisissant le format désiré) à partir de la première année pour laquelle il y a des données, 2016.
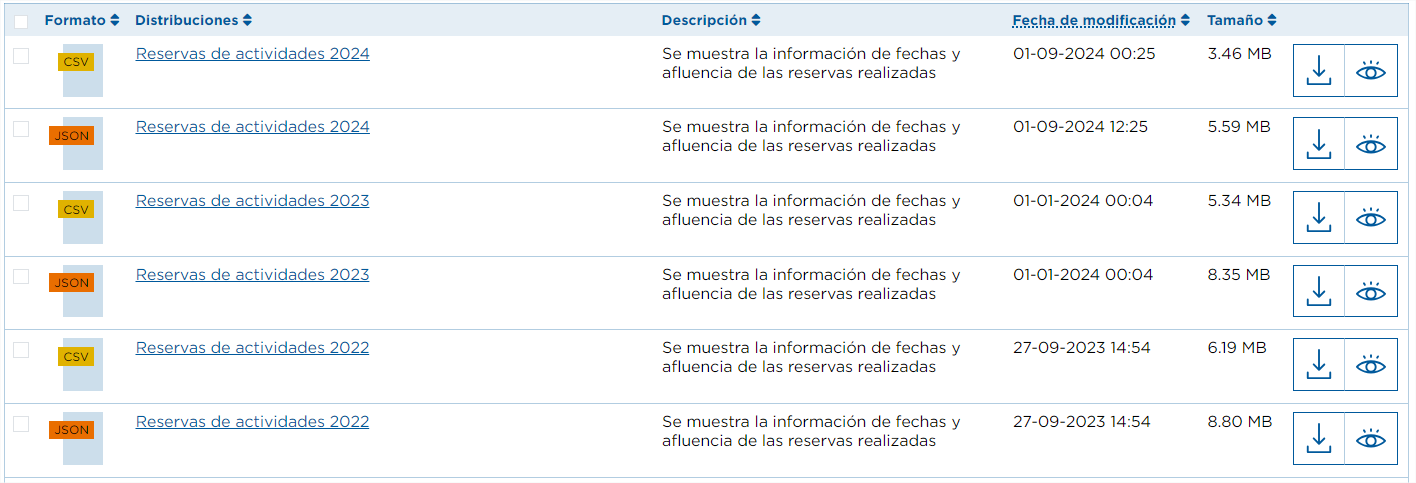
Pour le processus d'automatisation, nous devons répéter les étapes ci-dessus :
- Utilisez le point de terminaison "package_search" dans la section "Datasets" de l'API du portail qui se trouve dans le bloc Data.
- Dans le paramètre "q", indiquez le nom exact de l'ensemble de données à rechercher, entre guillemets (par exemple, "Réservations d'activités de nature à Tenerife") ou un ou plusieurs mots pour effectuer la recherche (par exemple, Réservations d'activités de nature).
- Nous vérifions que nous obtenons des résultats et, s'il y en a plus d'un, nous conservons le tableau des résultats dont le titre coïncide avec le nom de l'ensemble de données.

- Enfin, dans le tableau des ressources, nous conservons les URL pour lesquelles le format des métadonnées est "CSV" et le nom contient "Réservation d'activités".
De cette façon, lorsque les données avec les 2025 réserves sont publiées, nous pouvons également collecter automatiquement l'URL de la nouvelle ressource à travers ce processus, de sorte que nous puissions télécharger les données.
Dans ce cas, nous pourrions également copier les URL manuellement, car, après tout, les ressources se trouvent dans le même ensemble de données et il nous suffirait de cliquer avec le bouton droit de la souris pour obtenir le lien. Bien entendu, nous devrons nous rappeler d'accéder chaque année à l'ensemble de données pour copier l'URL de la nouvelle ressource mise à jour.
3. Différents ensembles de données
Dans ce cas, nous avons des ensembles de données différents, mais ils ont la "même" relation de ressource. Dans ce cas, l'automatisation est non seulement intéressante, mais aussi recommandée. Par exemple, si nous sommes intéressés par l'analyse des données météorologiques quotidiennes de toutes les stations de Ténériffe, le portail dispose actuellement de données pour 62 stations, chacune avec des ressources annuelles jusqu'en 2024, à la fois en format CSV et JSON. Cela représente des centaines de ressources, dont il faudrait collecter l'URL, et d'autres sont ajoutées chaque année.
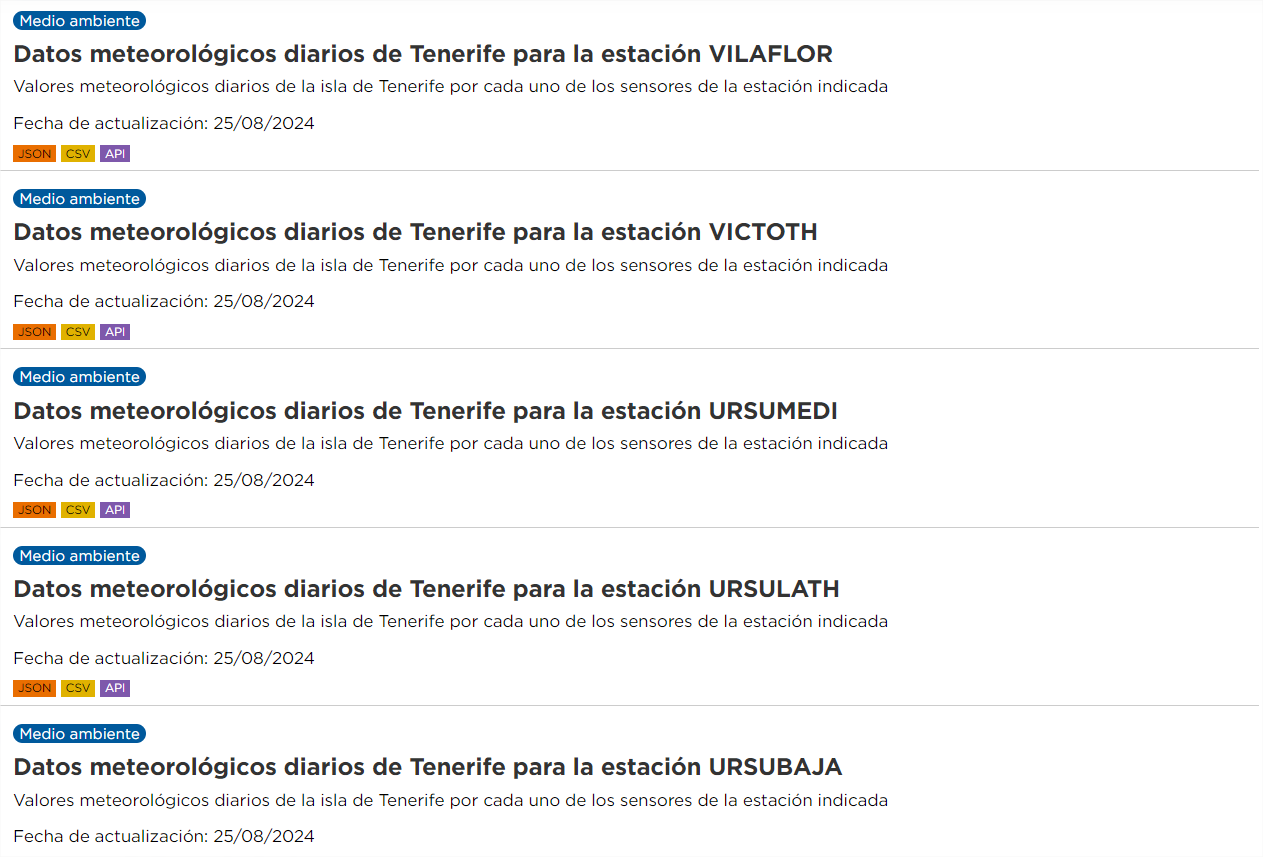
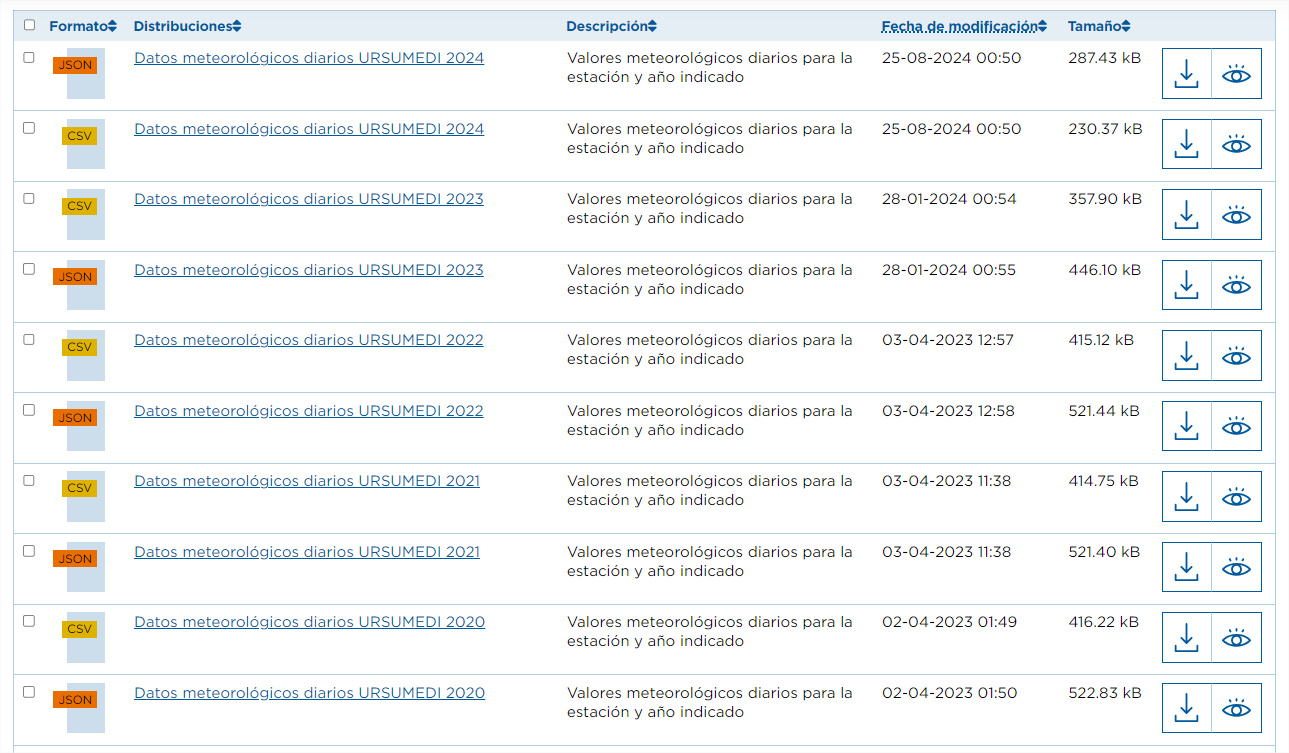
Les étapes à suivre dans ce cas sont les mêmes que dans le cas précédent, sauf que le paramètre "q" doit contenir une valeur générique, par exemple, "Données météorologiques quotidiennes" (n'oubliez pas de le mettre entre guillemets).
Ce point d'accès est limité à 10 résultats ou ensembles de données, nous devons donc lancer ce point d'accès en modifiant le paramètre rows afin qu'il renvoie plus d'ensembles.
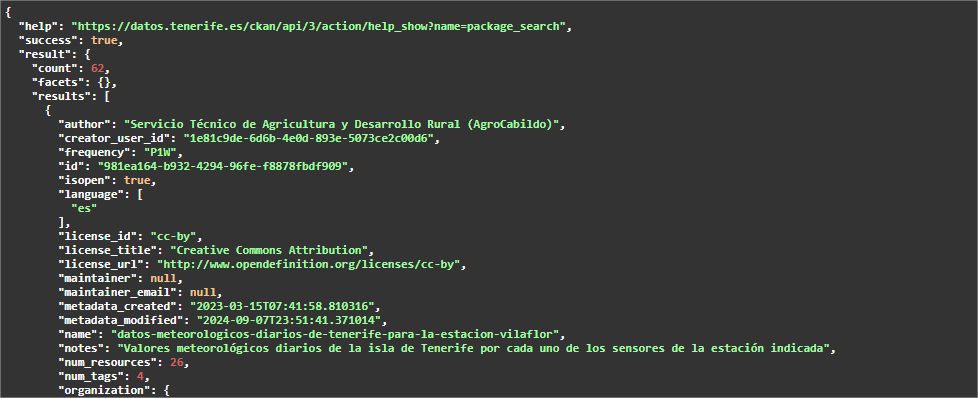
Comme le nombre de résultats attendus est de 62, nous pouvons indiquer en lignes, par exemple, 100. Comme swagger est utilisé comme documentation de l'API et que le JSON à récupérer est assez volumineux, ce qui peut causer des problèmes de chargement sur la page portail, il est conseillé de lancer la requête directement dans un autre onglet du navigateur. L'URL à exécuter serait la suivante
https://datos.tenerife.es/ckan/api/3/action/package_search?q=%22Datos%20meteorol%C3%B3gicos%20diarios%22&rows=100
Comme dans le cas précédent, nous filtrerons les URL des ressources dont le nom contient "Données météorologiques quotidiennes" et dont le format est "CSV".
Pour plus d'informations sur l'utilisation de l'API du portail de données ouvertes du Cabildo, voir l'article "API du portail de données ouvertes : consommation automatisée de données". Une vidéo sur l'utilisation de l'API du portail de données ouvertes est également disponible.