


Automatic update of data depending on its publication in the portal
The Open Data Portal of the Cabildo de Tenerife allows you to consult or download the most recent datasets automatically or manually.
In order to have an updated history , we must follow a series of steps. Depending on how the data is updated in the portal, we can distinguish three casuistry:
1. Same data set and same resource
Of the three cases to consider, this is the most straightforward, since it only depends on one URL. Once the dataset resource is located, we can use the tool of our choice to obtain the data through the resource URL. Two methods can be used to obtain this URL.
The first and simplest method is to right-click on the download button of the resource and select the Copy link address option.
For example, this is the case for the dataset "Afluencia a Barranco de Masca". This dataset has the resource "Afluencia a Barranco de Masca".
This set has the resource "Affluence of access to Barranco de Masca by age" where the number of people who have accessed the ravine is recorded.
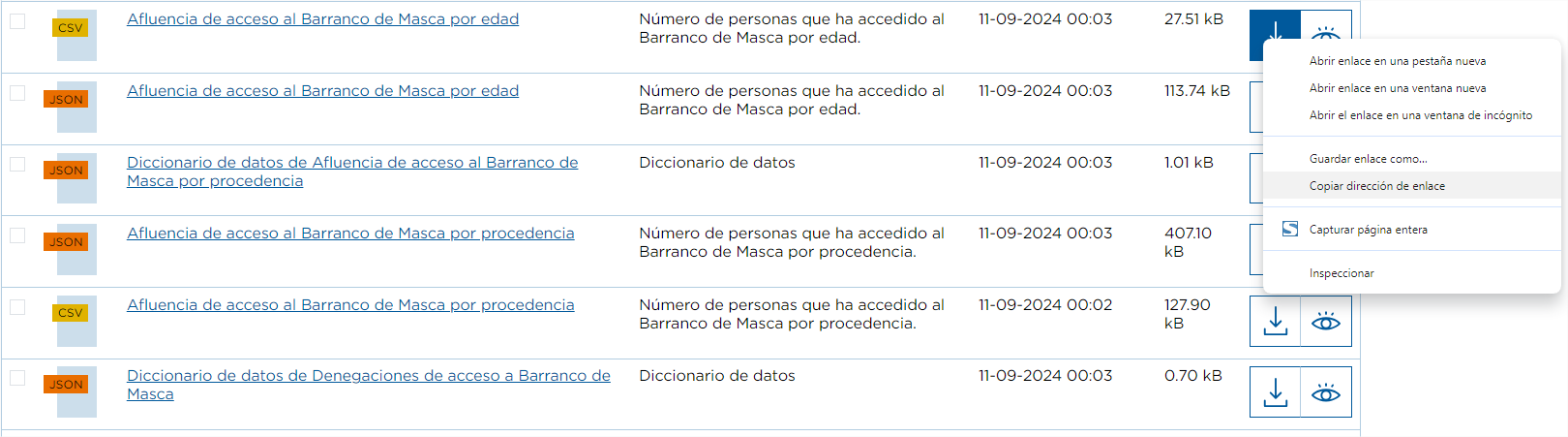
Performing the previous steps, we would copy its URL which is:
If we use this URL directly in the browser we would download the resource and, for example, we could also use it as a data source in a Power BI report so that when it is updated it always retrieves the latest available data.
In this example we have selected the CSV format, but we could do the same with any other type of format.
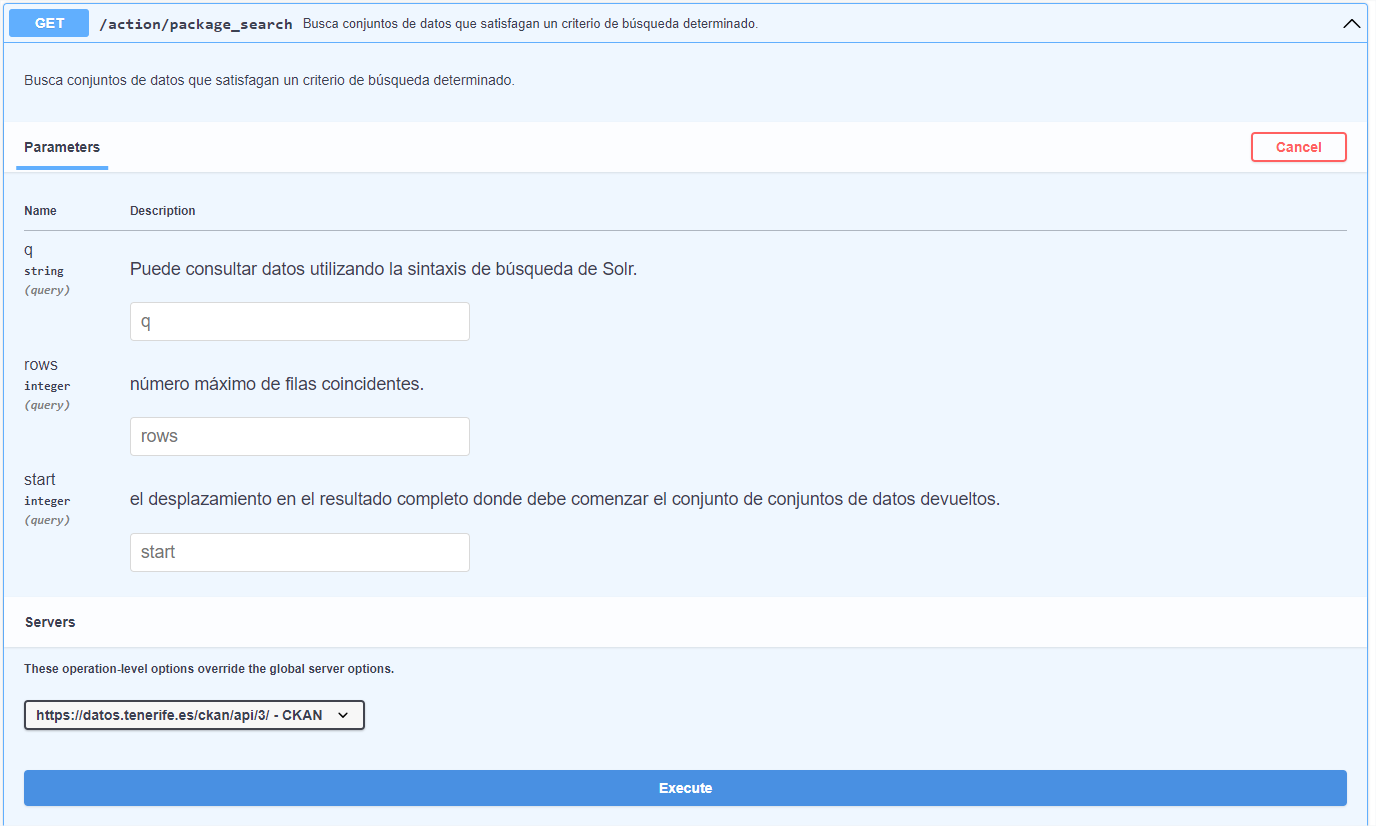
The second method to obtain the link needed for the download is through the portal API, which is located in the Data block.

Of all the endpoints that appear we use "package_search" from the "Datasets" section. This endpoint searches for the datasets that satisfy the search and displays in JSON format the metadata associated with the dataset, along with the resources available to it. After clicking the "Try it out" button, we will indicate the name of the dataset to search for "Afluencia a Barranco de Masca" in the "q" parameter and hit the "Execute" button.
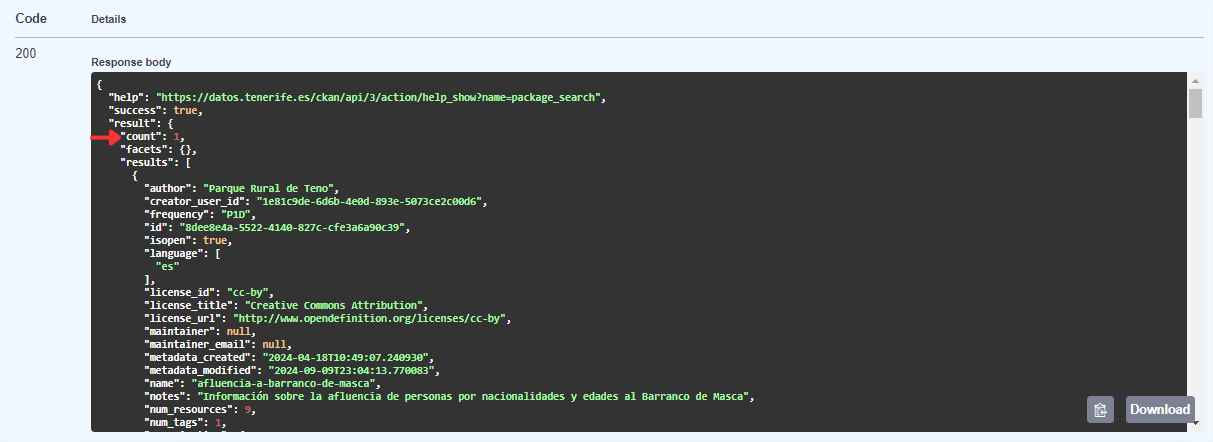
First, in addition to checking that there have been no errors (code 200), we can see how many datasets satisfy our search, in this case 1.
As we go down the result we can see the different metadata of the set, for example, itstitle (title) or the description(notes) among others.
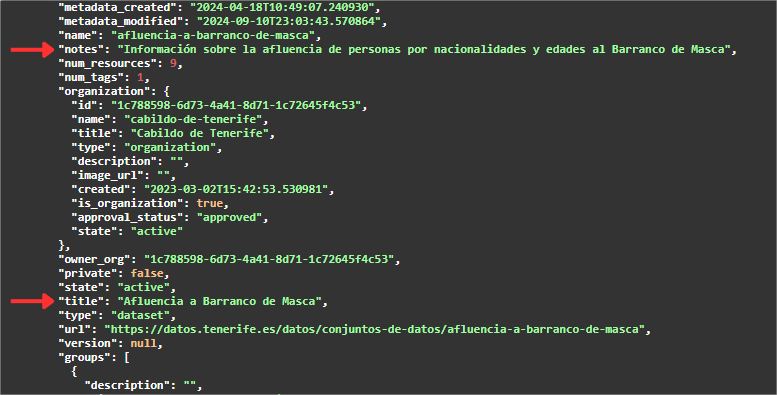
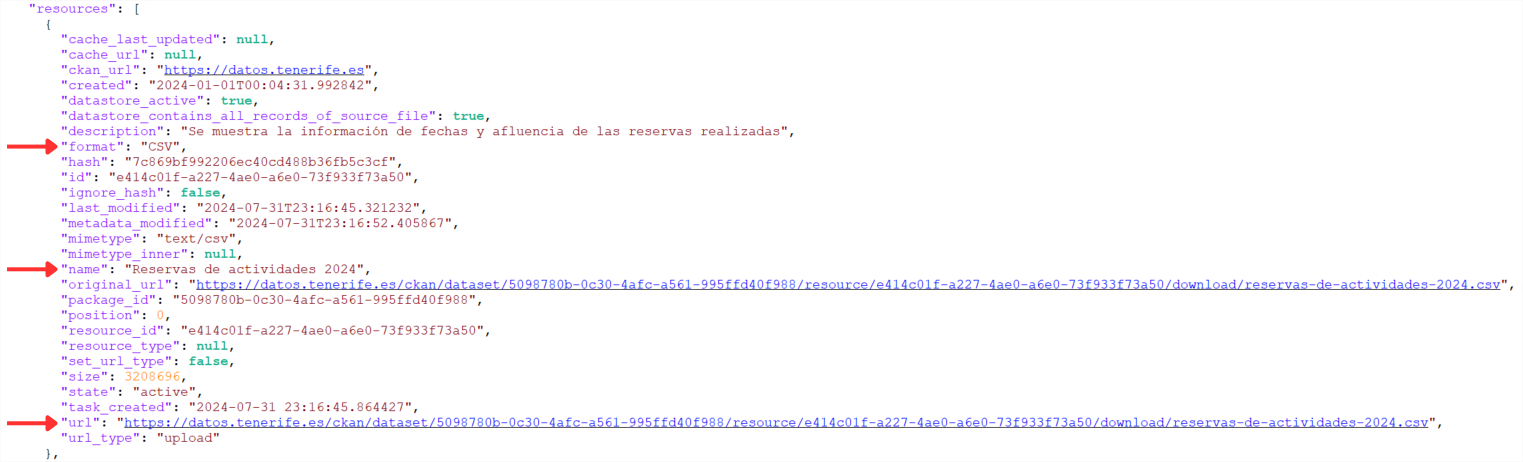
If we continue going down the JSON we will find an array ("resources": [ ]) with all the resources available in this dataset. For a better visualization or use, it is allowed to download this JSON.
Next, we must look for the value associated to the "url" tag of the resource that has as metadata:
- "name": "Affluence of access to Barranco de Masca by age".
- "format": "CSV".

Next, we must look for the value associated with the "url" tag of the resource that has as metadata:
- "name": "Affluence of access to the Barranco de Masca by age"
- "format": "CSV".
And in this way we obtain the same URL for the resource that we obtained with the first method. With this second method we could find out in a single API call the URLs of several resources at once, if necessary.
2. Same dataset and different resources
If in the previous case we depended on a single URL and the retrieval process could be done manually (because only one resource is updated), in this case, it is interesting to have an automation process that retrieves all the resources needed to form a history.
For example, in the dataset "Reserves of activities in nature in Tenerife" the resources are divided by years, showing the number of people performing an activity on a given date, so we should obtain all the URLs of the resources (choosing the desired format) from the first year for which there are data, 2016.
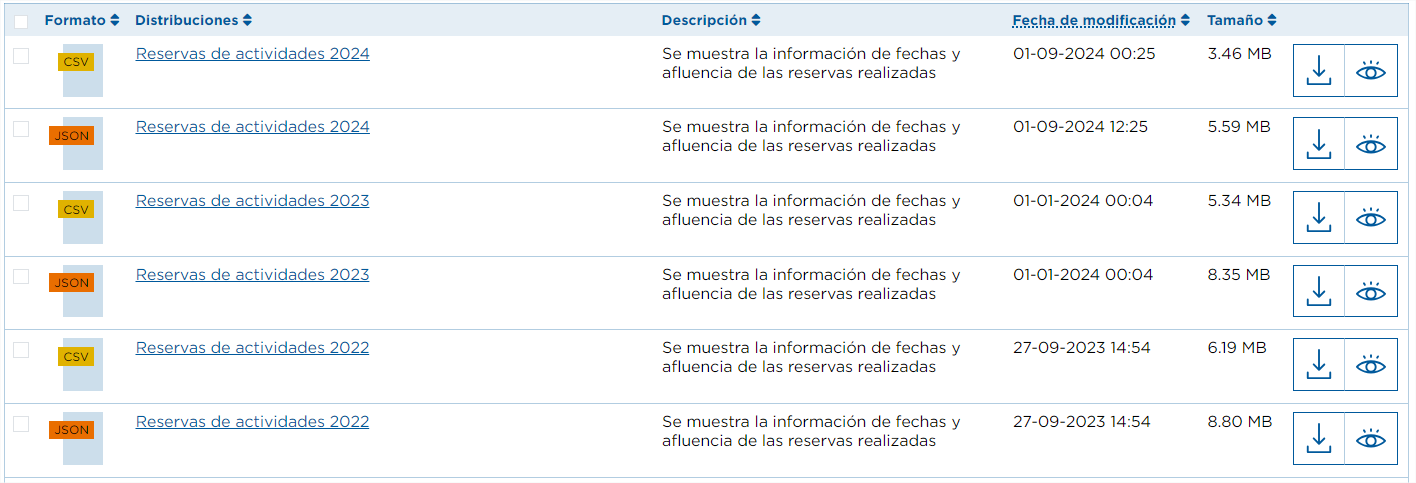
For the automation process we should repeat the steps indicated above:
- Use the "package_search" endpoint in the "Datasets" section, in the portal API found in the Data block.
- In the parameter "q" indicate the exact name of the dataset to search, in quotation marks (i.e. "Reservations of nature activities in Tenerife") or one or more words to perform the search (e.g. Reservations nature activities).
- Verify that we get results and, if there is more than one, we keep the array of results whose title matches the name of the dataset.

- Finally, from the array of resources, we keep those URLs for which the format metadata is "CSV" and name contains "Booking activities".
In this way, when the data with the 2025 reserves are published, we will also be able to automatically collect the URL of the new resource through this process, so that we can download the data.
In this case we could also copy the URLs manually, because, after all, the resources are in the same dataset and we would simply have to click with the right mouse button to obtain the link. Of course, we would have to remember to access the dataset annually to copy the URL of the new updated resource.
3. Different datasets
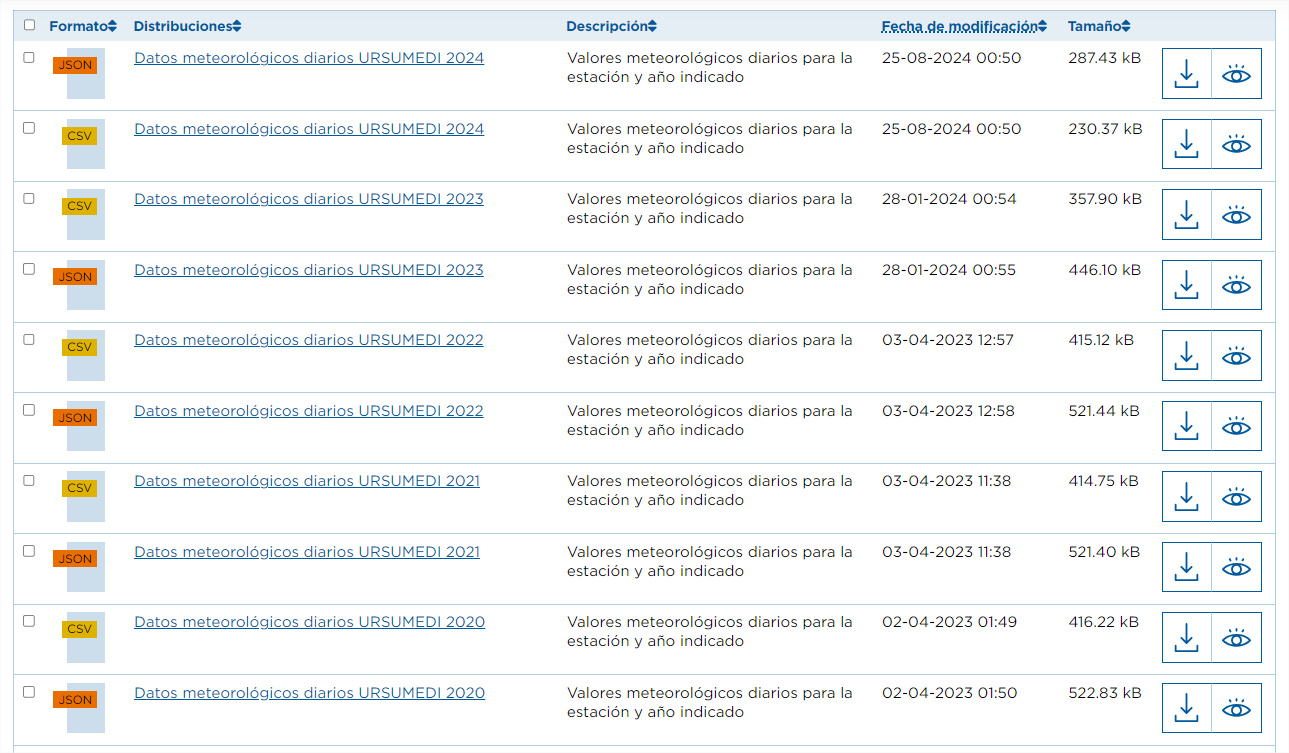
In this case we have different datasets, but they have the "same" resource relationship. For this case, automation is not only interesting again, but also recommended. For example, if we are interested in analyzing daily weather data from all stations in Tenerife, the portal currently has data for 62 stations, each of them has annual resources until 2024, both in CSV and JSON format. This means hundreds of resources, of which the URL would have to be collected and more are added every year.
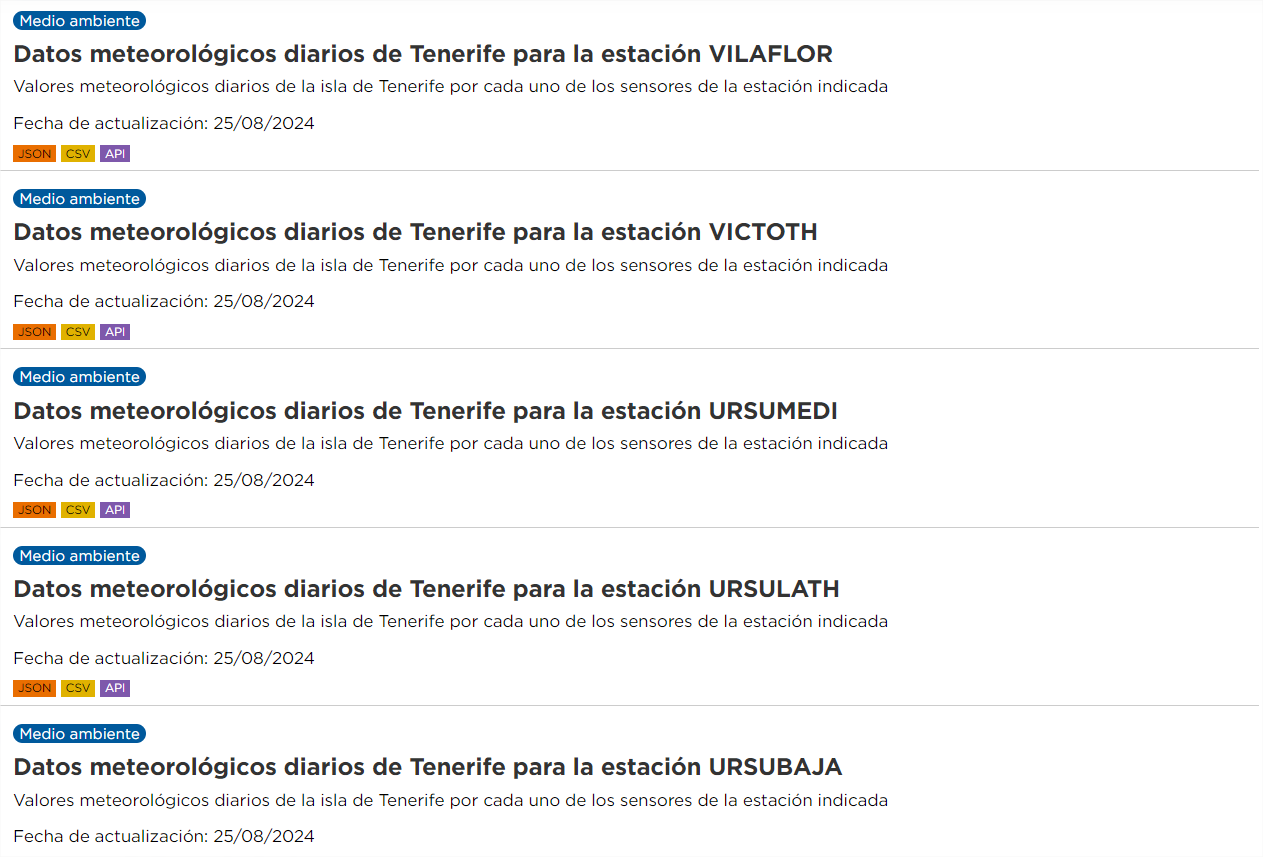
The steps to perform in this case are the same as in the previous case, except that the parameter "q" must contain a generic value, for example, "Daily weather data" (remember to put it in quotation marks).
This endpoint is limited to 10 results or data sets, so we must launch this endpoint by modifying the rows parameter to return more sets.
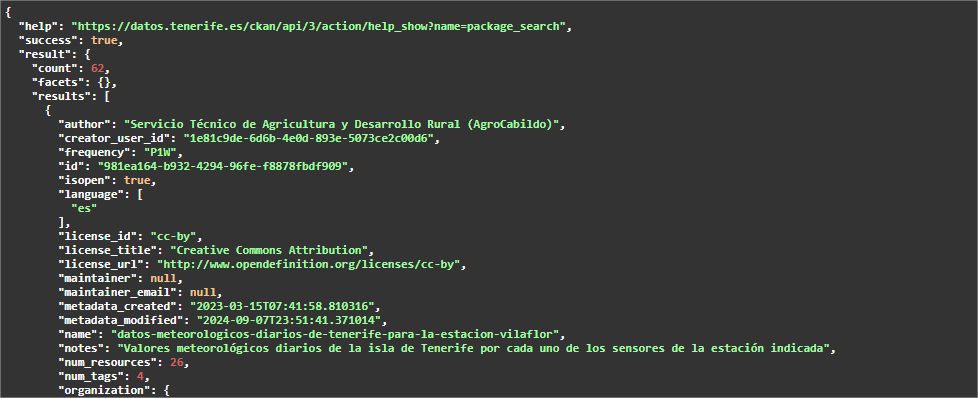
Since the expected number of results is 62, we can indicate in rows, for example, 100. Since swagger is used as API documentation and the JSON to retrieve is quite large, which can cause loading problems on the portal page, it is advisable to launch the query directly in another browser tab. The URL to execute would be:
https://datos.tenerife.es/ckan/api/3/action/package_search?q=%22Datos%20meteorol%C3%B3gicos%20diarios%22&rows=100
As we did in the previous case, we would filter the URLs of the resources whose name contains "Daily weather data" and format is "CSV".
For more information on how to use the API of the Cabildo's open data portal, see the article "API of the Open Data Portal: automated data consumption". A video on how to use the Open Data Portal API is also available.