


SPARQL point: o que é e como utilizá-lo
O portal de dados abertos do Cabildo de Tenerife inclui um ponto SPARQL, que permite efetuar consultas para procurar conjuntos que contenham uma palavra específica ou recursos específicos.
O SPARQL(SPARQL Protocol and RDF Query Language) é uma linguagem de consulta concebida para recuperar e manipular dados armazenados no formato RDF (Resource Description Framework), um padrão para representar informações na Web semântica.
A ferramenta utilizada para armazenar e consultar estes dados é o Virtuoso, que armazena os dados sob a forma de grafos RDF formados por triplas sujeito-predicado-objeto, que representam as relações entre entidades e os valores que estas têm para determinadas propriedades.
De seguida, explicaremos mais detalhadamente o que é e como se utiliza.
ACESSO AO PONTO SPARQL
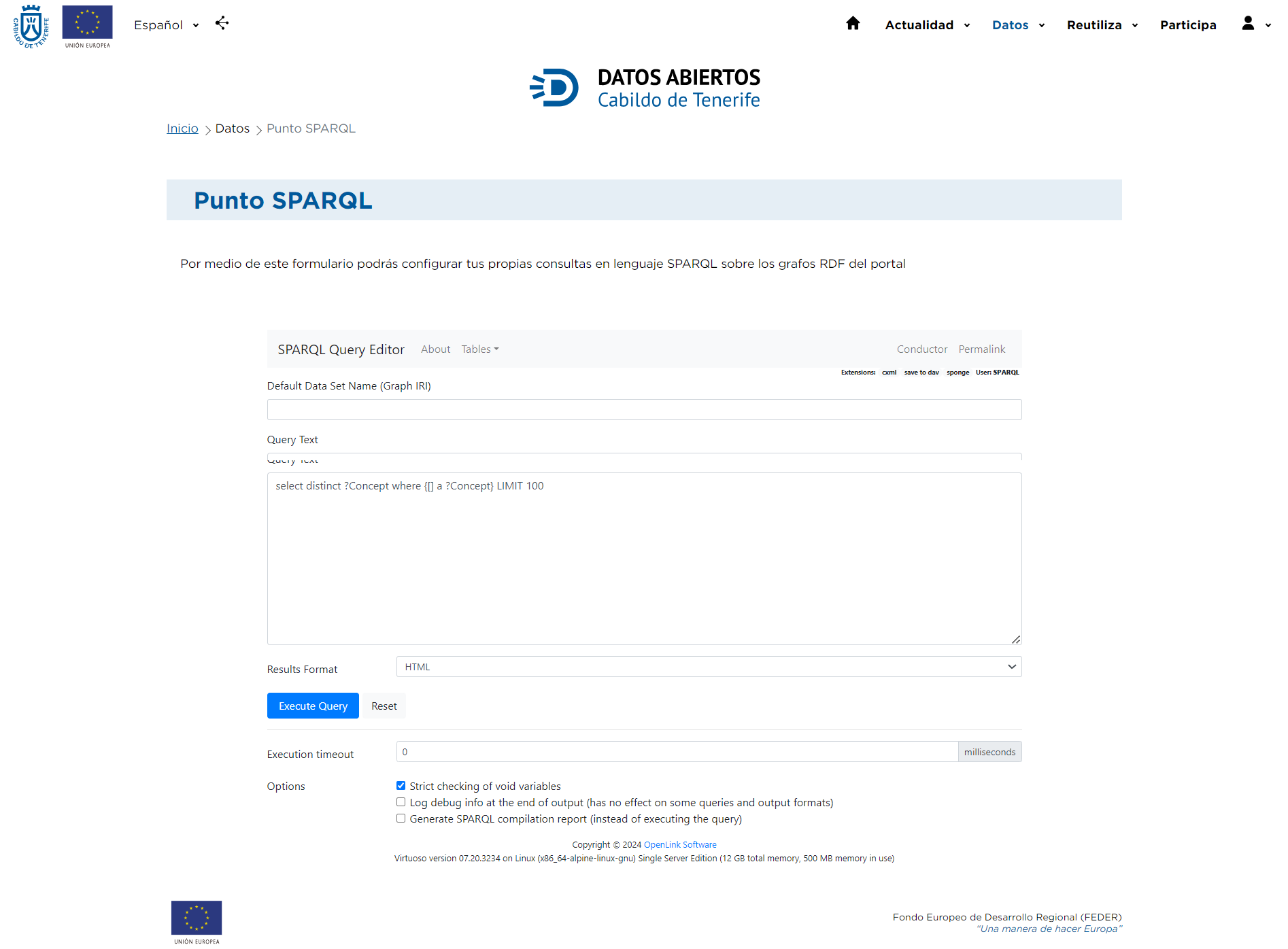
Para aceder ao Ponto SPARQL do portal datos.tenerife.es é necessário ativar o separador Dados, situado na parte superior esquerda da página inicial.

Depois de aceder ao Ponto SPARQL, aparecerá um ecrã com diferentes opções que lhe permitirão restringir a sua pesquisa.
Com o SPARQL é possível criar consultas complexas que relacionam elementos entre si, tirando partido da estrutura gráfica RDF. A sintaxe SPARQL é semelhante à das consultas SQL, uma vez que é constituída por operadores SELECT, WHERE, FILTER, ORDER BY, etc.
Incorpora uma série de prefixos(PREFIX) que servem para abreviar URIs(Uniform Resource Identifier) longos e tornar as consultas mais legíveis e compactas.
Na caixa Texto da Consulta pode introduzir as consultas pretendidas, seguindo as indicações explicadas nos pontos seguintes, e executá-las clicando no botão Executar Consulta. Uma vez executada a consulta, o resultado será apresentado num novo separador. Para voltar a lançar outra consulta, utilize o botão de retrocesso do navegador ou clique nas opções da tabela SPARQL | HTML5. Finalmente, clicando no botão Reset, eliminamos a consulta introduzida e vemos a consulta de exemplo.
Por outro lado, no Ponto SPARQL do portal de Dados Abertos do Cabildo, pode escolher o formato em que deseja obter os resultados da consulta utilizando os diferentes valores do menu pendente "Formato dos resultados": Auto, HTML, Folha de cálculo, XML, JSON, Javascript, Turtle, RDF/XML, N-Triples, CSV e TSV.
Além disso, na parte inferior da página, pode escolher entre três opções diferentes:
- Verificação rigorosa de variáveis nulas: Quando executa uma consulta SPARQL, pode utilizar variáveis que não têm um valor atribuído (variáveis nulas). Esta opção indica se pretende que o sistema efectue uma verificação rigorosa destas variáveis para garantir que não são utilizadas de forma incorrecta ou inadequada na consulta. Se ativar esta opção, o sistema pode lançar um erro se encontrar variáveis vazias que não deveriam estar lá, de acordo com as regras da consulta.
- Registar informações de depuração no final da saída: Esta opção sugere que, quando activada, os detalhes de depuração serão registados no final da saída da consulta. As informações de depuração geralmente incluem detalhes internos do processo de execução da consulta e podem ser úteis para identificar problemas ou entender como a consulta é processada. Observe, no entanto, que esta opção pode não ser eficaz para algumas consultas ou formatos de saída específicos.
- Gerar relatório de compilação SPARQL: Em vez de executar a consulta SPARQL, esta opção indica que será gerado um relatório mostrando como a consulta seria compilada ou processada internamente. Este relatório pode ser útil para compreender o desempenho ou a eficiência da consulta sem ter de a executar na totalidade. Pode ajudar a identificar possíveis optimizações antes da execução efectiva.
UTILIZAR SPARQL POINT
Para compreender o SPARQL, o melhor é utilizar um exemplo e explicá-lo parte a parte.
Suponhamos que temos uma série de gráficos RDF que descrevem informações ou metadados sobre conjuntos de dados e recursos publicados, com informações sobre o título, a descrição, o editor, o formato, etc.
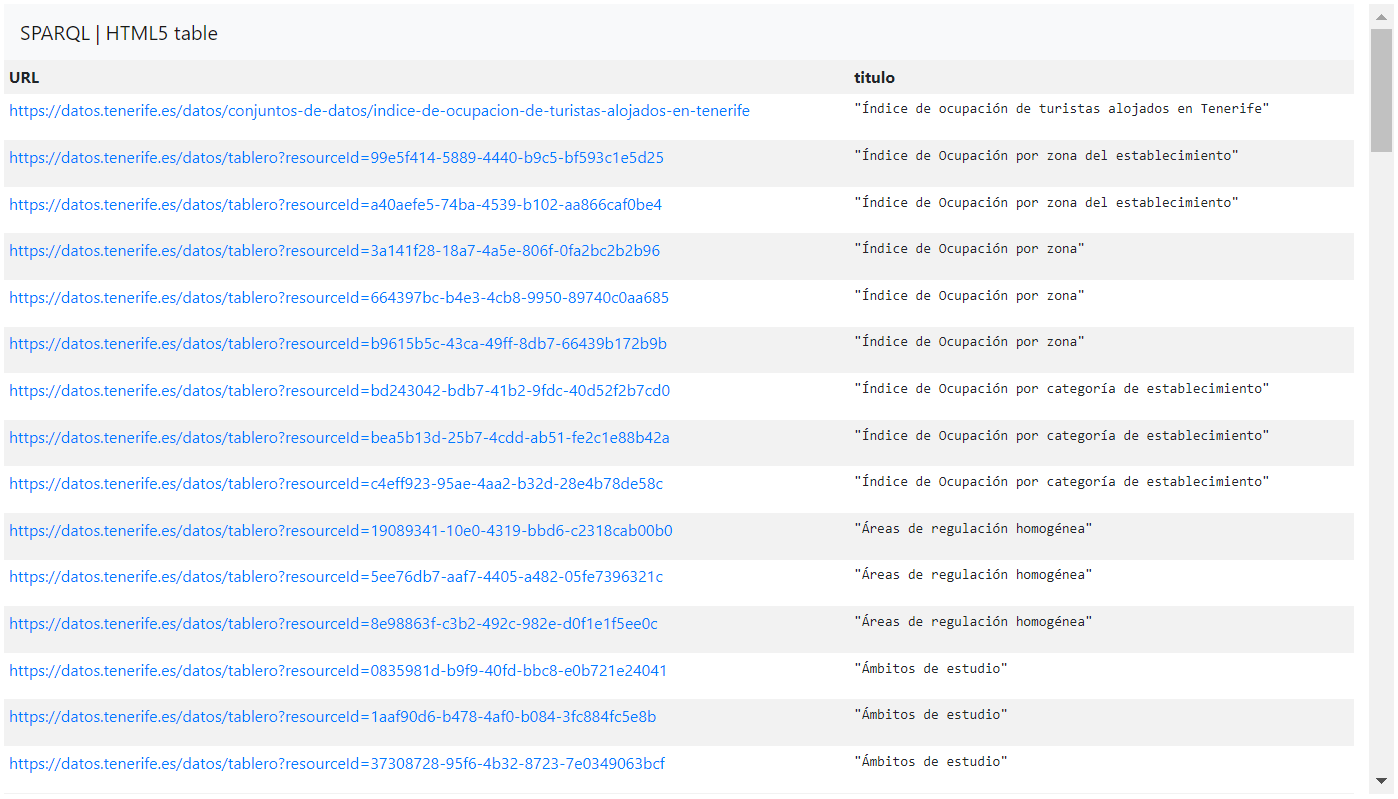
Neste caso, faríamos uma simples consulta SPARQL para obter os primeiros cem conjuntos de dados ou recursos e as suas ligações ordenadas por título:
PREFIXO dct: <http://purl.org/dc/terms/> Selecionar distinto ?URL ?título where { ?URL dct:título ?título } order by desc(?título) LIMIT 100A explicação do código é a seguinte:
- PREFIX: Este prefixo atribui o pseudónimo"dct" ao URI de base " http://purl.org/dc/terms/". É utilizado para abreviar os URIs na consulta.
- SELECT: Especifica as variáveis que pretendemos obter nos resultados da consulta. Neste caso, queremos obter os primeiros cem conjuntos de dados ou recursos com os respectivos URLs. A cláusula distinct garante que apenas resultados únicos sejam exibidos (sem repetições).
- WHERE: Define o padrão triplo RDF a procurar na rede:
- ?URL dct:title ?title: Aqui estamos à procura de triplas onde algum conjunto tem um título. A variável ?title será usada para representar esses títulos.
Também podemos obter qualquer outro tipo de informação que tenhamos no RDF, descrição, editora...
Desta forma, a consulta SPARQL dar-nos-ia resultados como os seguintes:
Referindo-nos ao portal de dados abertos do Cabildo de Tenerife, mostraremos uma série de exemplos de consultas SPARQL para obter informações sobre os dados publicados.
Neste caso, o Virtuoso baseia-se no catálogo de metadados do portal disponibilizado em https://datos.tenerife.es/es/datos/tablero?resourceId=17e64992-df93-4c8d-b9a5-5c860b1e978c para obter os metadados dos conjuntos e recursos publicados para criar os gráficos RDF.
EXEMPLOS
De seguida, explicamos, com diferentes exemplos, os diferentes tipos de pesquisa que podem ser efectuados no portal.
- Obter o nome e o link de todos os conjuntos de dados e recursos do portal:Desta forma, pode obter o nome e o link (URL) de todos os conjuntos de dados e os seus recursos (distribuições) publicados no portal .
PREFIXO dct: <http://purl.org/dc/terms/> SELECT distinct ?nome ?nome ?URL WHERE{ ?URL dct:título ?nome }
- Filtragem por cadeias de texto:
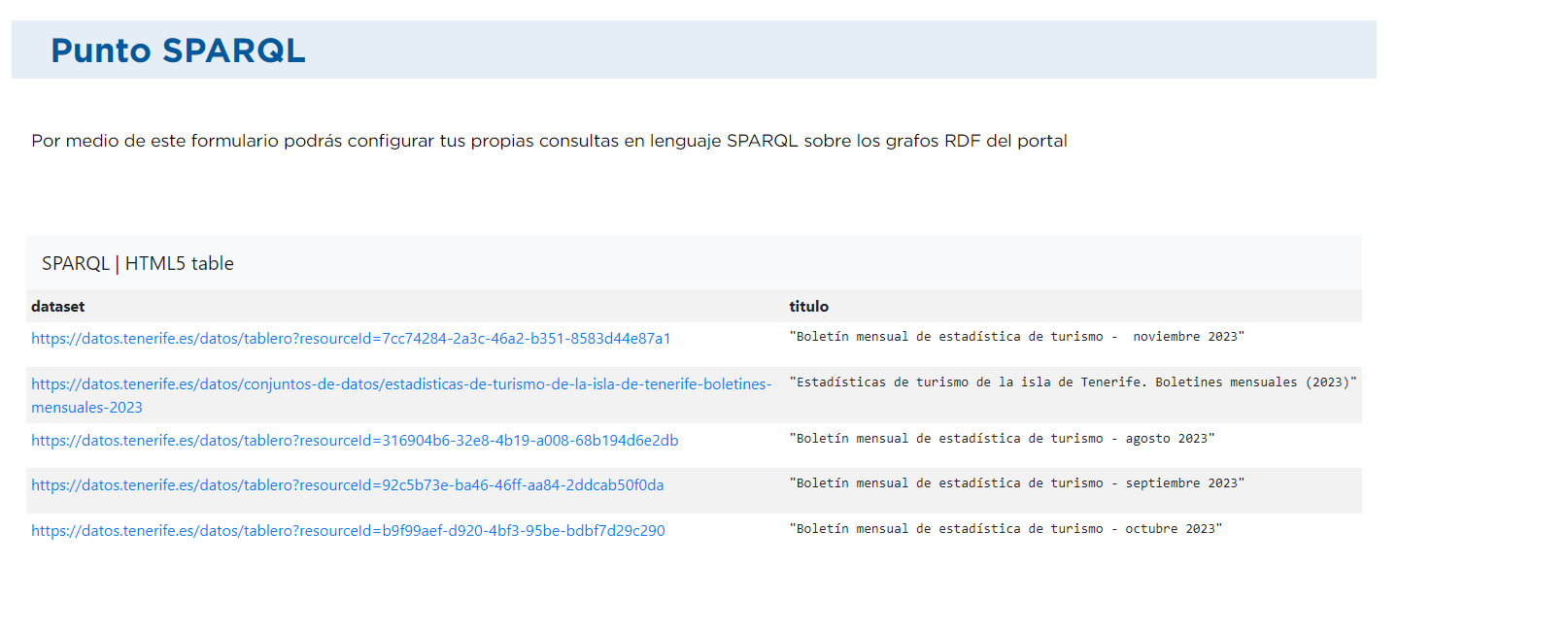
Neste caso queremos recuperar os conjuntos que têm a palavra "turismo" no seu título (?title):
PREFIX dct: <http://purl.org/dc/terms/> PREFIX dcat: <http://www.w3.org/ns/dcat#> SELECT * WHERE { ?dataset dct:title ?title . FILTER (CONTAINS(LCASE(?title), "tourism")) }O resultado teria o seguinte aspeto:
- Procurar um conjunto de dados ou recurso pelo seu nome específico:
Obter os URLs dos conjuntos de dados ou recursos com o título "Paragens de autocarro".
PREFIXO dct: <http://purl.org/dc/terms/> SELECT * WHERE { ?URL dct:title "Paragens de autocarro" }
- Filtrar por tipo de recurso
No portal de dados abertos, um conjunto de dados pode ter o mesmo recurso em vários formatos (distribuições), pelo que, ao efetuar uma consulta no ponto SPARQL, obteremos resultados repetidos com o mesmo título, que podemos diferenciar adicionando uma coluna de tipo de recurso.
Na seguinte consulta, utilizaremos a cláusula FILTER para procurar os conjuntos com a palavra "centros" e obteremos as suas ligações, títulos e formatos:
PREFIXO dct: <http://purl.org/dc/terms/> SELECT WHERE { ?URL dct:title ?title. ?URL dct:formato ?formato . FILTER (CONTAINS(LCASE(?title), "centres")) } order by asc(?title)
Existe também a possibilidade de filtrar para obter apenas recursos do tipo GeoJSON.
Neste caso, existem duas formas de pesquisar, cujo resultado seria o mesmo:
- Usando FILTER:
PREFIXO dct: <http://purl.org/dc/terms/> SELECT * WHERE { ?URL dct:title ?title. ?URL dct:formato ?formato. FILTER (CONTAINS(LCASE(?title), "centros")) FILTRO (CONTAINS(LCASE(?format), "geojson")) }) } - Indicando a cadeia de texto no tripleto:
PREFIXO dct: <http://purl.org/dc/terms/> SELECT * WHERE { ?URL dct:title ?title. ?URL dct:format "GeoJSON" FILTER (CONTAINS(LCASE(?title), "centres")) } }
- Obter informação sobre o editor dos dados:
Esta informação é recolhida no campo dcat:contactPoint . Na seguinte consulta, vamos obter os conjuntos cujo editor ou ponto de contacto é o Serviço Técnico de Agricultura e Desenvolvimento Rural (AgroCabildo):
PREFIXO dct: <http://purl.org/dc/terms/> PREFIXO dcat: <http://www.w3.org/ns/dcat#> SELECT distinct ?URL ?title ?contact_point WHERE { ?URL dct:title ?title. ?URL dcat:contactPoint ?ponto_de_contacto. FILTRO (CONTAINS(LCASE(STR(?ponto_de_contacto)), "serviço técnico de agricultura") }) } ORDER BY ASC(?título)
Até aqui, a formação sobre o SPARQL Point de datos.tenerife.es, mas encorajamo-lo a continuar a aprender mais sobre o nosso portal e todas as possibilidades que oferece.