


Atualização automática dos dados em função da sua publicação no portal
O Portal de Dados Abertos do Cabildo de Tenerife permite-lhe consultar ou descarregar os conjuntos de dados mais recentes de forma automática ou manual.
Para ter um histórico atualizado , é necessário seguir uma série de passos. Dependendo da forma como os dados são actualizados no portal, podemos distinguir três tipos de casos:
1. O mesmo conjunto de dados e o mesmo recurso
Dos três casos a considerar, este é o mais simples, pois depende apenas de um URL. Uma vez localizado o recurso do conjunto de dados, podemos utilizar a ferramenta da nossa escolha para obter os dados através do URL do recurso. Podem ser utilizados dois métodos para obter este URL.
O primeiro e mais simples é clicar com o botão direito do rato no botão de download do recurso e selecionar a opção Copiar endereço do link.
Por exemplo, este é o caso do conjunto de dados "Afluência a Barranco de Masca". Este conjunto de dados tem o recurso "Afluência a Barranco de Masca".
Este conjunto de dados tem o recurso "Influência do acesso ao Barranco de Masca por idade" onde se regista o número de pessoas que acederam ao Barranco.
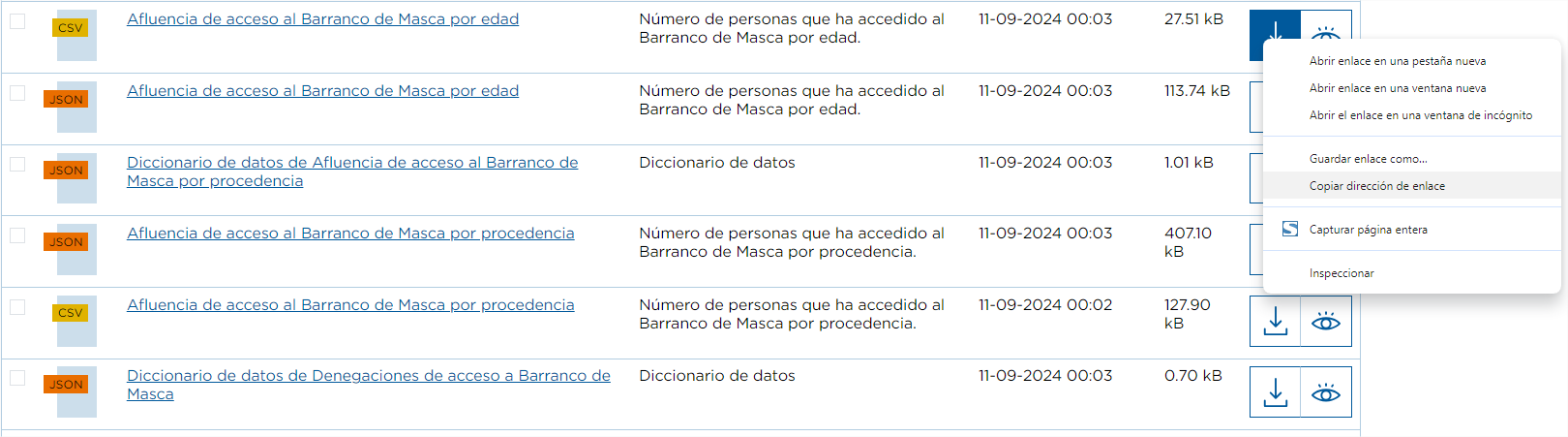
Ao efetuar os passos anteriores, copiaríamos o seu URL, que é:
Se utilizarmos este URL diretamente no navegador, descarregamos o recurso e, por exemplo, também o podemos utilizar como fonte de dados num relatório do Power BI para que, quando este for atualizado, obtenha sempre os últimos dados disponíveis.
Neste exemplo, selecionámos o formato CSV, mas poderíamos fazer o mesmo com qualquer outro tipo de formato.
O segundo método para obter a ligação necessária para a descarga é através da API do portal, que se encontra no bloco Dados.

De todos os endpoints que aparecem, utilizamos o "package_search" da secção "Datasets". Este ponto final procura os conjuntos de dados que satisfazem a pesquisa e apresenta em formato JSON os metadados associados ao conjunto de dados, juntamente com os recursos disponíveis para o mesmo. Depois de clicar no botão "Try it out", indicamos o nome do conjunto de dados a pesquisar "Afluencia a Barranco de Masca" no parâmetro "q" e clicamos no botão "Execute".
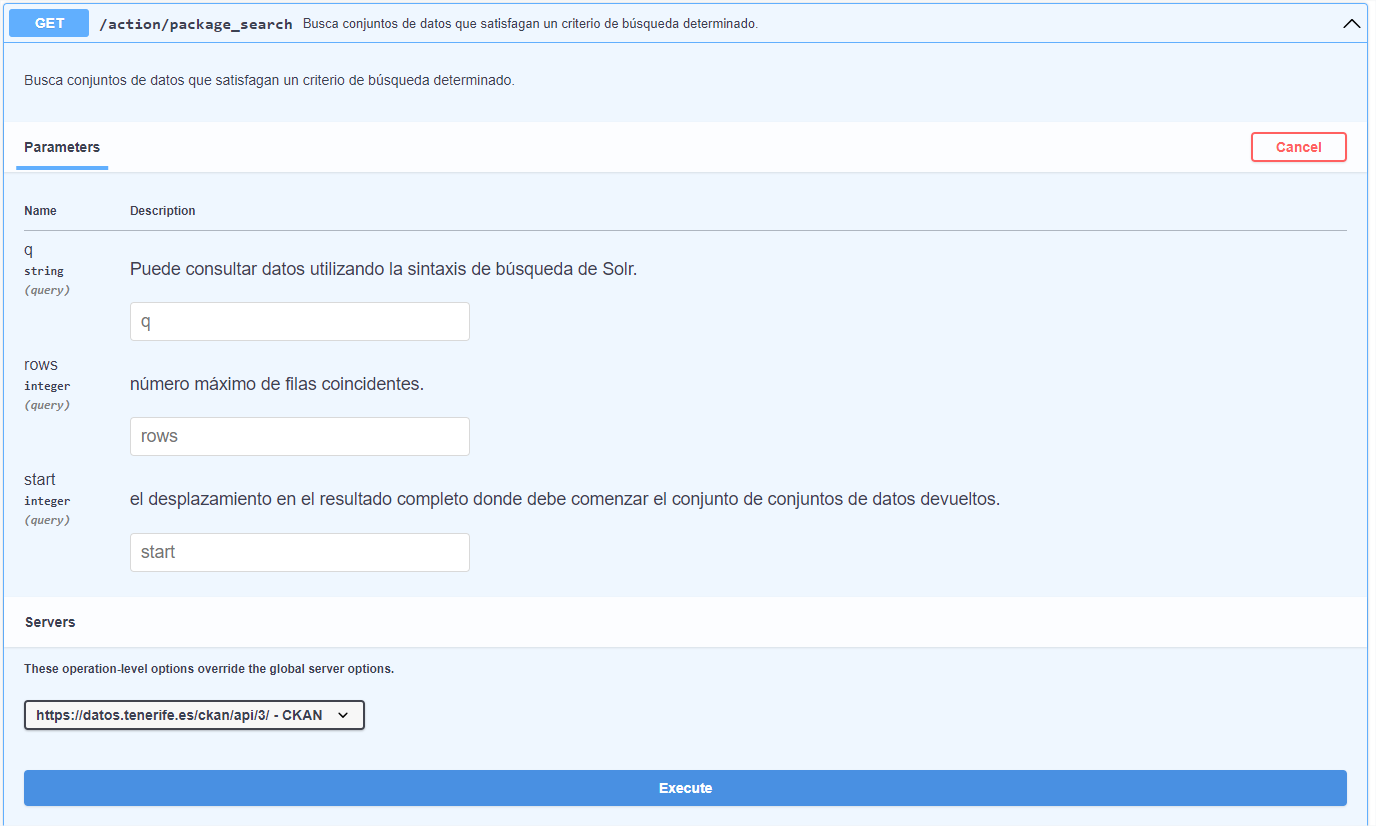
Em primeiro lugar, para além de verificar que não houve erros (código 200), podemos ver quantos conjuntos de dados satisfazem a nossa pesquisa, neste caso 1.
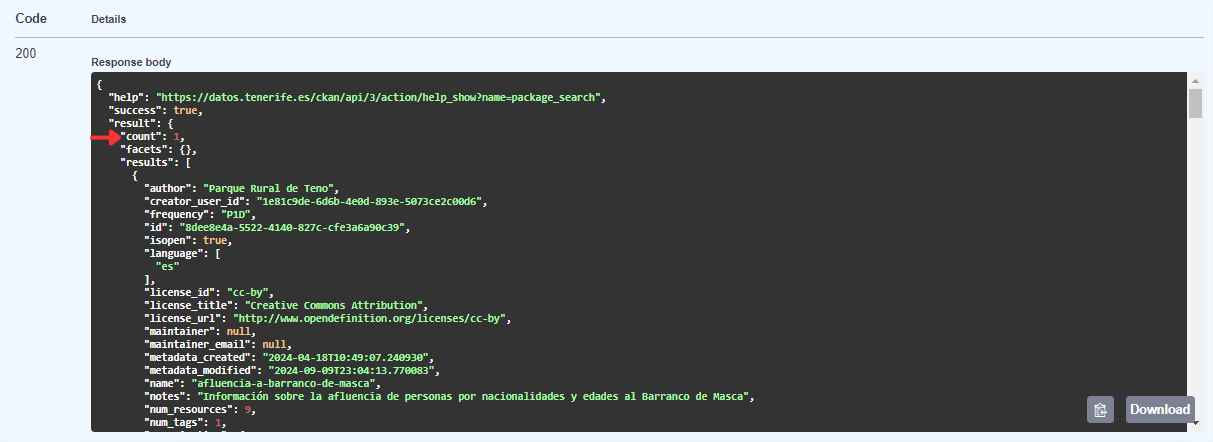
À medida que vamos descendo o resultado, podemos ver os diferentes metadados do conjunto, por exemplo,o seutítulo (title) ou a descrição(notes), entre outros.
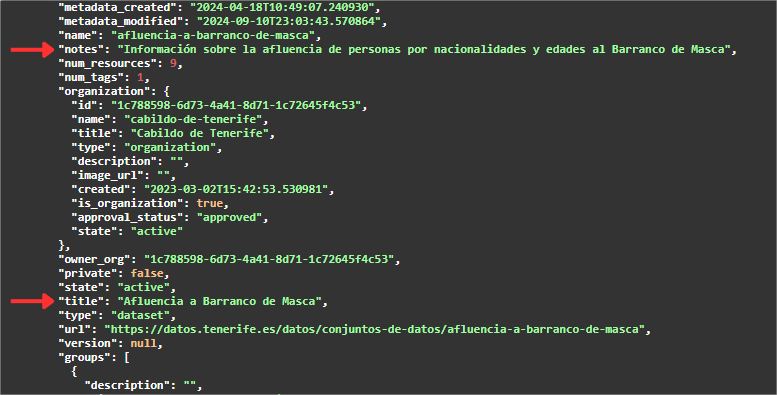
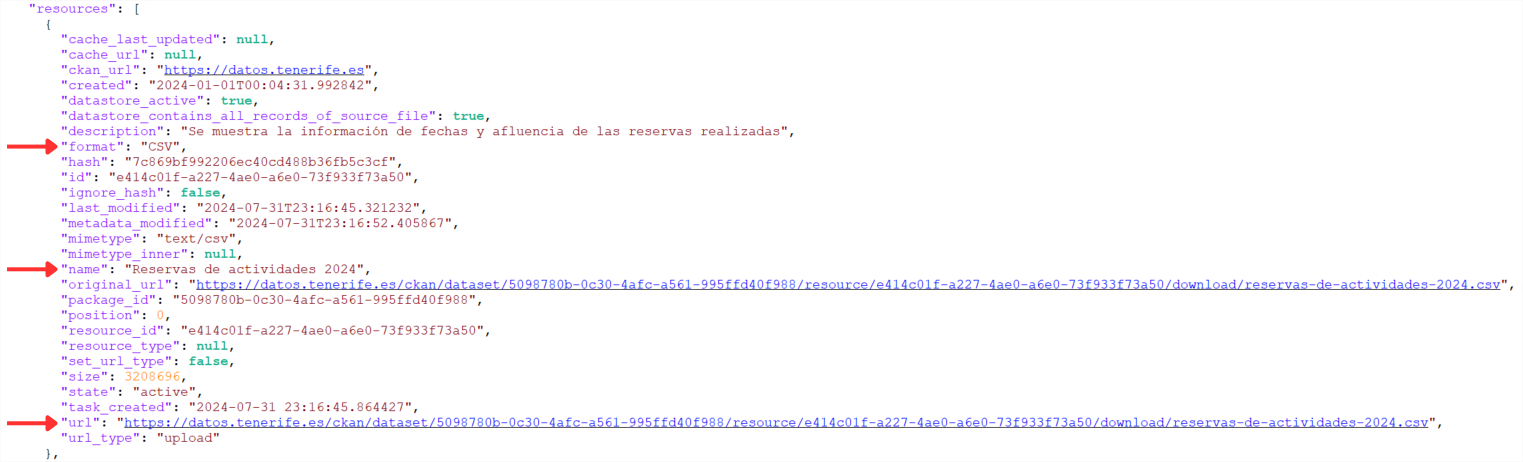
Se continuarmos a percorrer o JSON, encontraremos uma matriz ("resources": [ ]) com todos os recursos disponíveis para este conjunto de dados. Para uma melhor visualização ou utilização, é permitido descarregar este JSON.
De seguida, devemos procurar o valor associado à etiqueta "url" do recurso que tem como metadados:
- "name": "Influência do acesso ao Barranco de Masca por idade".
- "formato": "CSV".

De seguida, devemos procurar o valor associado à etiqueta "url" do recurso que tem como metadados:
- "name": "Afluencia de acceso al Barranco de Masca por edad".
- "formato: "CSV".
Desta forma, obtemos o mesmo URL para o recurso que obtivemos com o primeiro método. Com este segundo método, podemos descobrir numa única chamada à API os URLs de vários recursos ao mesmo tempo, se necessário.
2. Mesmo conjunto de dados e recursos diferentes
Se no caso anterior dependíamos de um único URL e o processo de obtenção podia ser feito manualmente (porque apenas um recurso é atualizado), neste caso, é interessante ter um processo de automatização que obtenha todos os recursos necessários para formar um histórico .
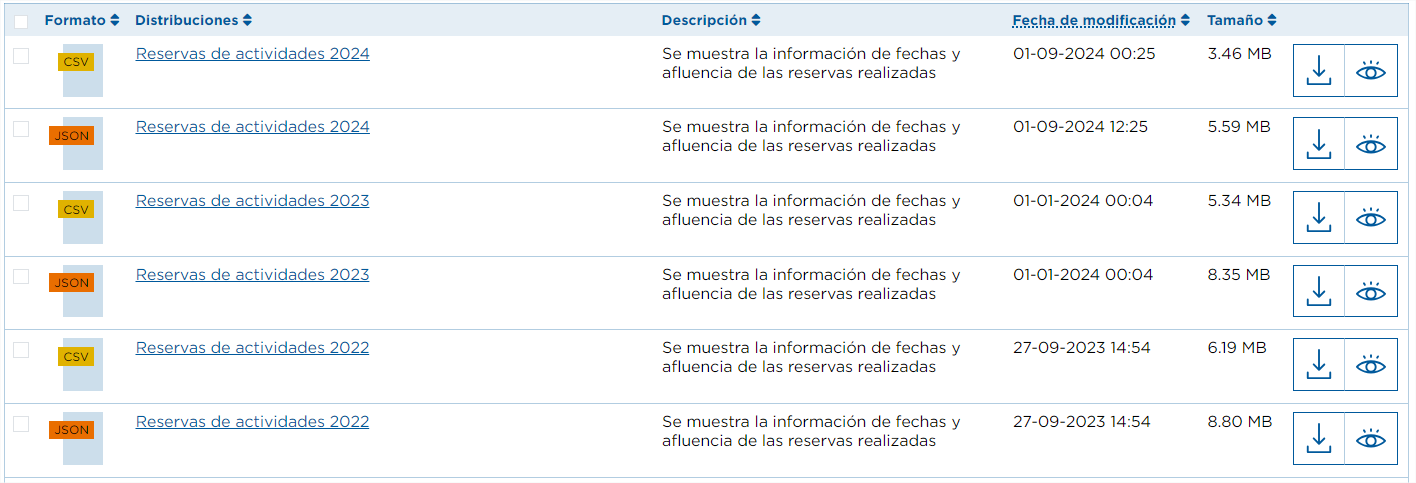
Por exemplo, no conjunto de dados "Reservas de actividades naturais em Tenerife", os recursos estão divididos por anos, mostrando o número de pessoas que realizam uma atividade numa determinada data, pelo que devemos obter todos os URLs dos recursos (escolhendo o formato pretendido) a partir do primeiro ano para o qual existem dados, 2016.
Para o processo de automatização, devemos repetir os passos anteriores:
- Utilizar o endpoint "package_search" na secção "Datasets" da API do portal, que se encontra no bloco Data.
- No parâmetro "q", indique o nome exato do conjunto de dados a pesquisar, entre aspas (por exemplo, "Reservas de actividades na natureza em Tenerife") ou uma ou mais palavras para efetuar a pesquisa (por exemplo, Reservas de actividades na natureza).
- Verificamos que obtemos resultados e, se houver mais do que um, guardamos a matriz de resultados cujo título coincide com o nome do conjunto de dados.

- Finalmente, da matriz de recursos guardamos os URLs para os quais os metadados de formato são "CSV" e o nome contém "Reserva de actividades".
Desta forma, quando os dados com as reservas 2025 forem publicados, podemos também recolher automaticamente o URL do novo recurso através deste processo, para que possamos descarregar os dados.
Neste caso, também poderíamos copiar os URLs manualmente, porque, afinal, os recursos estão no mesmo conjunto de dados e bastaria clicar com o botão direito do rato para obter a ligação. Claro que teríamos de nos lembrar de aceder ao conjunto de dados anualmente para copiar o URL do novo recurso atualizado.
3. Conjuntos de dados diferentes
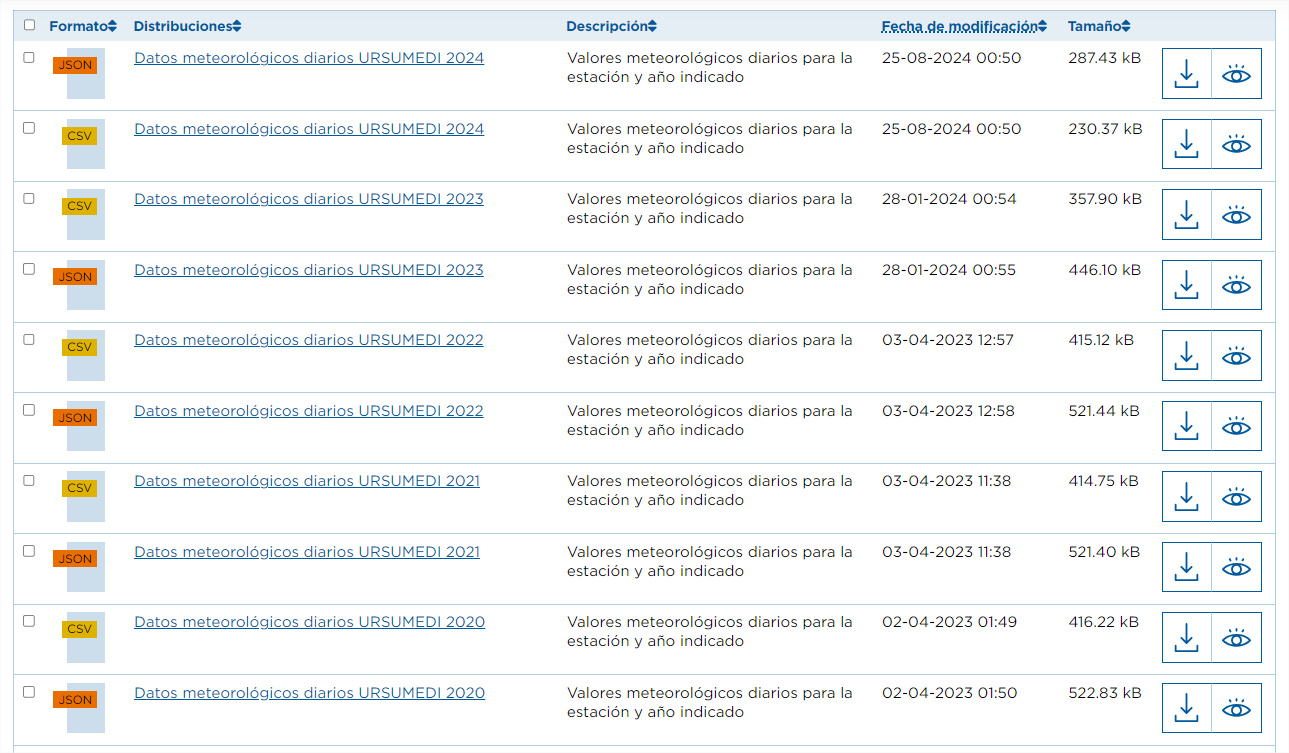
Neste caso, temos conjuntos de dados diferentes, mas que têm a "mesma" relação de recursos. Para este caso, a automatização não só é novamente interessante, como também recomendada. Por exemplo, se estivermos interessados em analisar os dados meteorológicos diários de todas as estações de Tenerife, o portal tem atualmente dados de 62 estações, cada uma com recursos anuais até 2024, tanto em formato CSV como JSON. Isto significa centenas de recursos, dos quais seria necessário recolher o URL, e todos os anos são acrescentados mais.
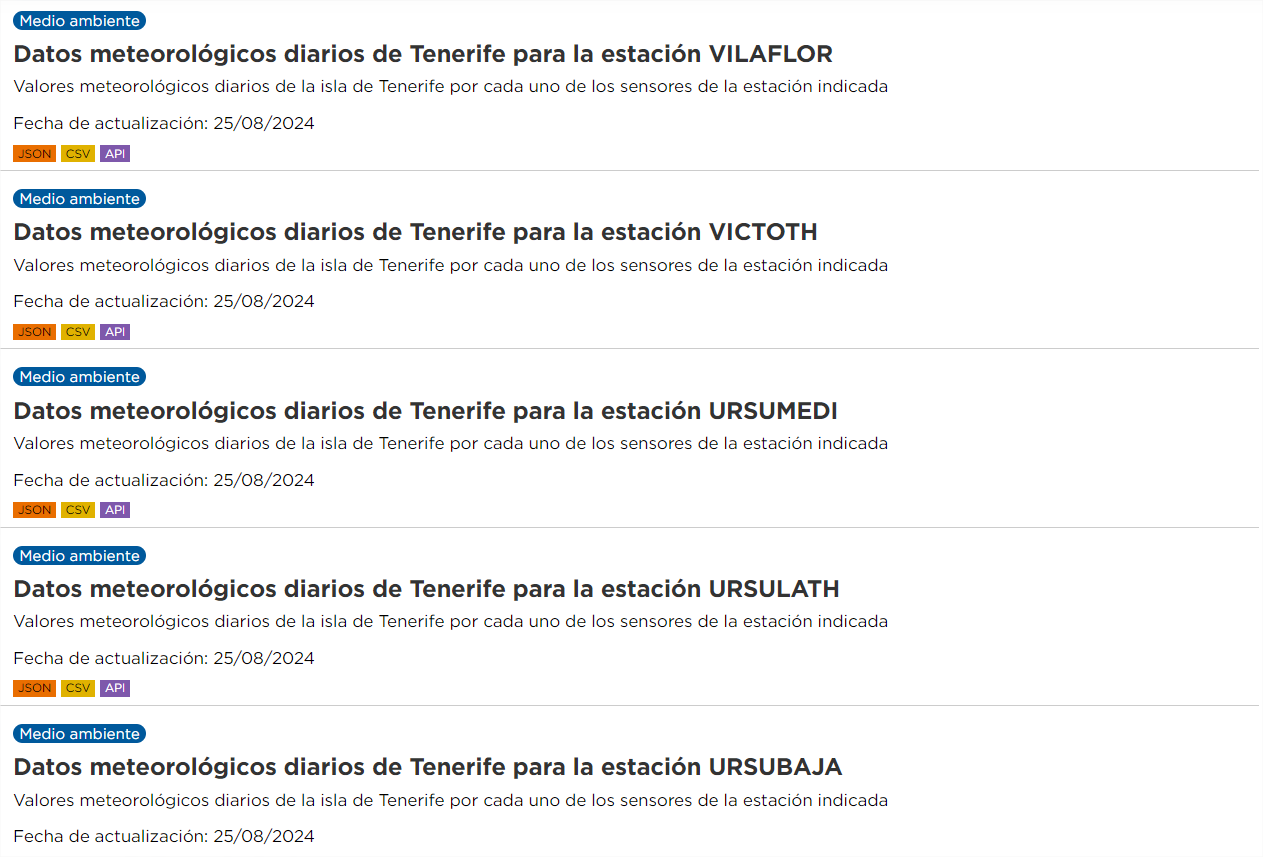
Os passos a executar neste caso são os mesmos que no caso anterior, exceto que o parâmetro "q" deve conter um valor genérico, por exemplo, "Daily weather data" (lembre-se de o colocar entre aspas).
Este endpoint está limitado a 10 resultados ou conjuntos de dados, pelo que devemos lançar este endpoint modificando o parâmetro rows para que devolva mais conjuntos.
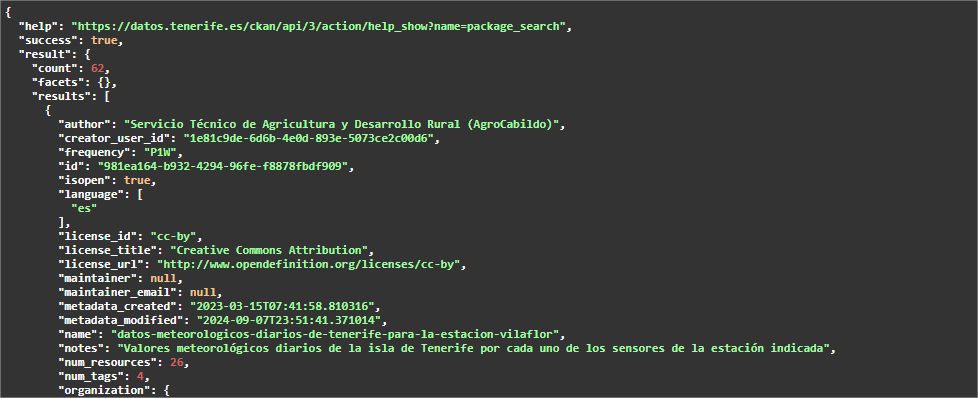
Como o número esperado de resultados é 62, podemos indicar em linhas, por exemplo, 100. Como o swagger é utilizado como documentação da API e o JSON a recuperar é bastante grande, o que pode causar problemas de carregamento na página do portal, é aconselhável lançar a consulta diretamente noutro separador do navegador. O URL a ser executado seria:
https://datos.tenerife.es/ckan/api/3/action/package_search?q=%22Datos%20meteorol%C3%B3gicos%20diarios%22&rows=100
Tal como fizemos no caso anterior, filtraríamos os URL dos recursos cujo nome contivesse "Daily weather data" e o formato fosse "CSV".
Para mais informações sobre como utilizar a API do portal de dados abertos do Cabildo, consulte o artigo "API do portal de dados abertos: consumo automático de dados". Também está disponível um vídeo sobre como utilizar a API do Portal de Dados Abertos.