


Punto SPARQL: qué es y cómo se utiliza
El portal de Datos Abiertos del Cabildo de Tenerife incluye un Punto SPARQL, que permite realizar consultas para buscar conjuntos que contengan una palabra específica o recursos concretos.
SPARQL (SPARQL Protocol and RDF Query Language) es un lenguaje de consulta diseñado para recuperar y manipular datos almacenados en formato RDF (Resource Description Framework), un estándar para representar información en la web semántica.
La herramienta utilizada para almacenar y consultar estos datos es Virtuoso, que almacena los datos en forma de grafos RDF formados por tripletas sujeto-predicado-objeto, que representan las relaciones entre entidades y los valores que tienen para ciertas propiedades.
A continuación, explicaremos más en detalle en qué consiste y cómo se utiliza.
Acceso al Punto SPARQL
Para acceder al Punto SPARQL del portal de datos.tenerife.es hay que desplegar la pestaña de Datos, ubicada en la parte superior izquierda de la página de Inicio.

Tras acceder a Punto SPARQL se muestra una pantalla en la que se distinguen diferentes opciones, que permitirán ir acotando la búsqueda.
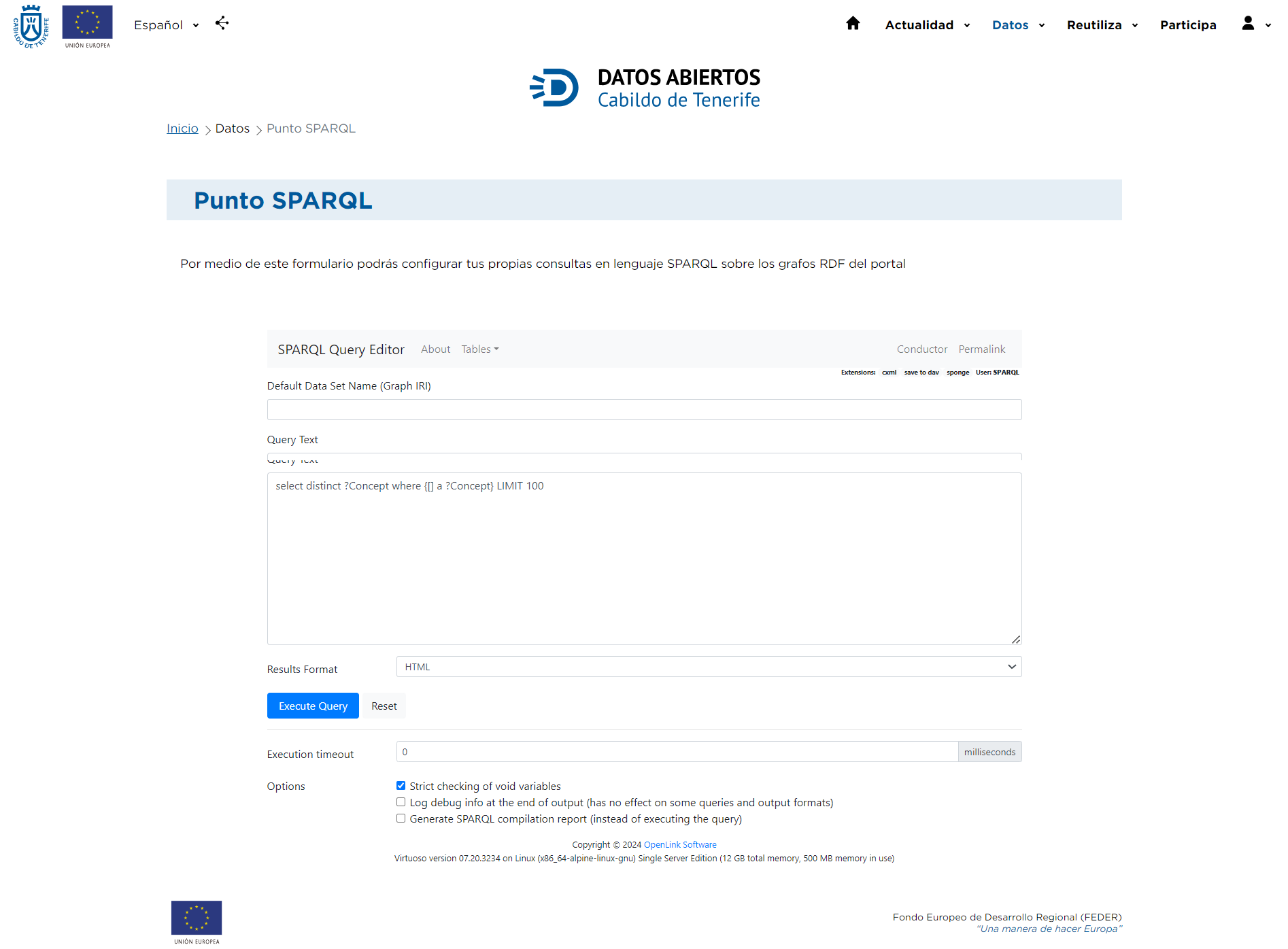
Con SPARQL es posible crear consultas complejas que relacionan elementos entre sí aprovechando la estructura de grafo de los RDF. La sintaxis de SPARQL es similar a las consultas SQL, ya que consta con operadores de SELECT, WHERE, FILTER, ORDER BY, etc.
Incorpora una serie de prefijos(PREFIX) que sirven para abreviar URI(Uniform Resource Identifier, identificadores de recursos) largos y hacer que las consultas sean más legibles y compactas.
En el cuadro de Query Text se pueden introducir las consultas deseadas, siguiendo las indicaciones que explicamos en los puntos siguientes y ejecutar haciendo clic en el botón Execute Query. Una vez ejecutada la consulta obtendremos el resultado en una nueva pestaña. Para volver a lanzar otra consulta o bien utilizamos el botón de retroceso del navegador o bien pulsamos en las opciones SPARQL | HTML5 table. Por último, dando al botón de Reset eliminamos la consulta introducida y vemos la consulta de ejemplo.
Por otra parte, en el Punto SPARQL del portal de Datos Abiertos del Cabildo se puede elegir el formato en el que obtener los resultados de la consulta utilizando los distintos valores del desplegable “Results format” (formato de resultados): Auto, HTML, SpreadSheet, XML, JSON, Javascript, Turtle, RDF/XML, N-Triples, CSV y TSV.
Además, en la parte inferior de la página se puede elegir entre tres opciones diferentes:
- Strict checking of void variables (Verificación estricta de variables vacías): Cuando ejecutas una consulta SPARQL, puedes utilizar variables que no tienen un valor asignado (variables vacías). Esta opción indica si deseas que el sistema realice una verificación estricta de estas variables para asegurarse de que no se utilicen incorrecta o inapropiadamente en tu consulta. Si activas esta opción, el sistema podría lanzar un error si encuentra variables vacías que no deberían estar ahí, según las reglas de la consulta.
- Log debug info at the end of output (Registrar información de depuración al final de la salida): Esta opción sugiere que, al activarla, se registrarán detalles de depuración al final del resultado de la consulta. La información de depuración suele incluir detalles internos del proceso de ejecución de la consulta y puede ser útil para identificar problemas o entender cómo se procesa la consulta. Sin embargo, ten en cuenta que esta opción puede no ser efectiva para algunas consultas o formatos de salida específicos.
- Generate SPARQL compilation report (Generar un informe de compilación SPARQL): En lugar de ejecutar la consulta SPARQL esta opción indica que se generará un informe que muestra cómo la consulta sería compilada o procesada internamente. Este informe podría ser útil para entender el rendimiento o la eficiencia de la consulta sin tener que ejecutarla completamente. Puede ayudar a identificar posibles optimizaciones antes de la ejecución real.
Utilización punto SPARQL
Para entender SPARQL lo mejor es utilizar un ejemplo y explicarlo parte por parte.
Supongamos que tenemos una serie de grafos RDF que describen información o metadatos sobre los conjuntos de datos y recursos publicados, teniendo información sobre el título, la descripción, el publicador, el formato, etc.
En este caso, realizaríamos una consulta SPARQL simple para obtener los cien primeros conjuntos de datos o recursos y sus enlaces ordenados por su título:
PREFIX dct: <http://purl.org/dc/terms/>
Select distinct ?URL ?titulo
where {
?URL dct:title ?titulo
}
order by desc(?titulo)
LIMIT 100
Le explicación del código es la siguiente:
- PREFIX: Este prefijo asigna el alias "dct" a la URI base " http://purl.org/dc/terms/". Se utiliza para abreviar las URI en la consulta.
- SELECT: Especifica las variables que queremos recuperar en los resultados de la consulta. En este caso, queremos obtener los cien primeros conjuntos de datos o recursos con sus URL. La cláusula distinct asegura que solo se muestren resultados únicos (que no haya repetidos).
- WHERE: Define el patrón de tripletas RDF que se busca en el grafo:
- ?URL dct:title ?titulo: Aquí estamos buscando triples donde algún conjunto tiene un título. La variable ?titulo se utilizará para representar esos títulos.
También se puede obtener cualquier otro tipo de información que tengamos en el RDF, descripción, publicador...
De este modo, la consulta SPARQL nos proporcionaría resultados como los siguientes:
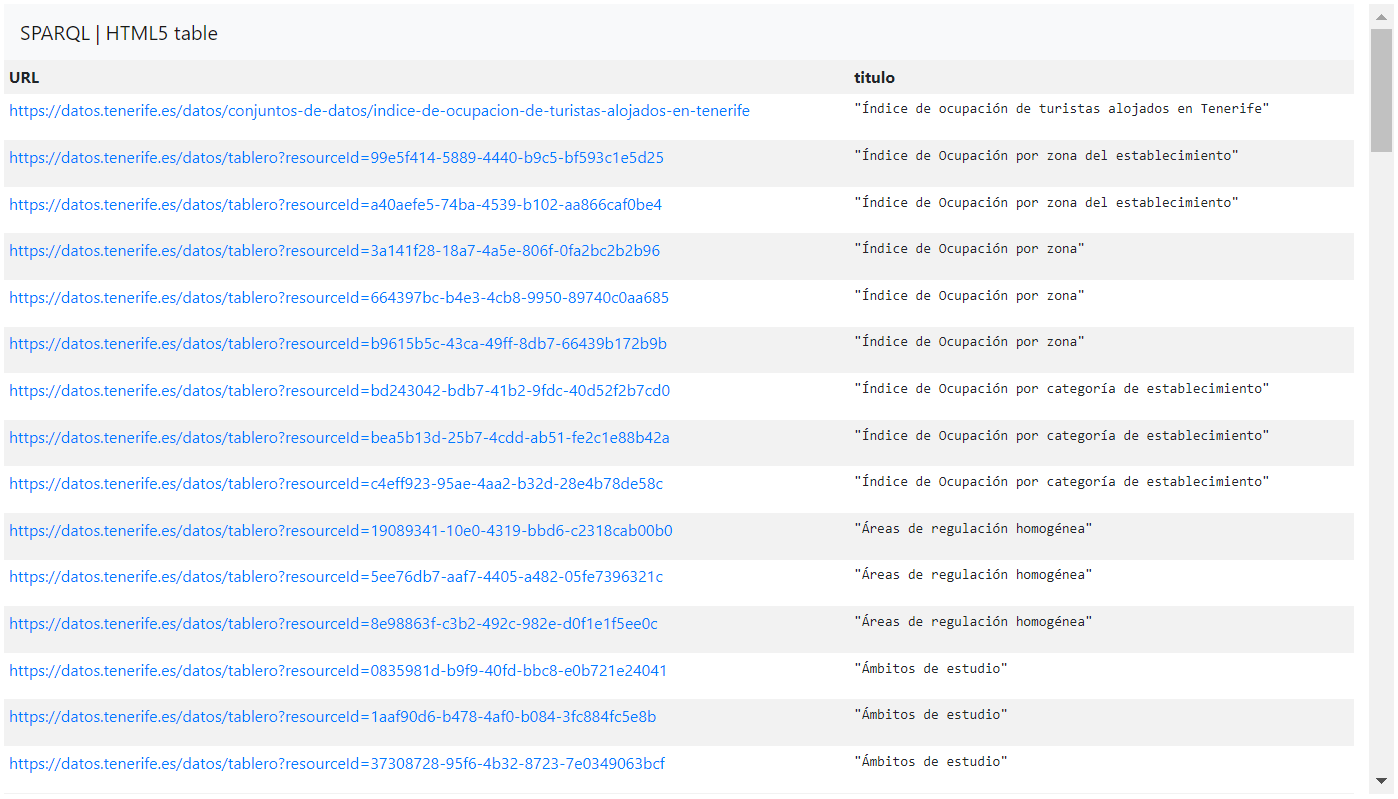
Referido al portal de Datos Abiertos del Cabildo de Tenerife mostraremos una serie de ejemplos de consultas SPARQL para recuperar información sobre los datos publicados.
En este caso, Virtuoso se basa en el catálogo de metadatos del portal proporcionado en https://datos.tenerife.es/es/datos/tablero?resourceId=17e64992-df93-4c8d-b9a5-5c860b1e978c para obtener los metadatos de los conjuntos y recursos publicados para crear los grafos RDF.
Ejemplos
A continuación, explicaremos, con diferentes ejemplos, los distintos tipos de búsqueda que se pueden realizar en el portal.
1. Obtener el nombre y enlace de todos los conjuntos de datos y recursos del portal:
De esta forma se puede obtener el nombre y el enlace (URL) de todos los conjuntos de datos y sus recursos (distribuciones) publicados en el portal.
PREFIX dct: <http://purl.org/dc/terms/>
SELECT distinct ?nombre ?URL
WHERE{
?URL dct:title ?nombre
}

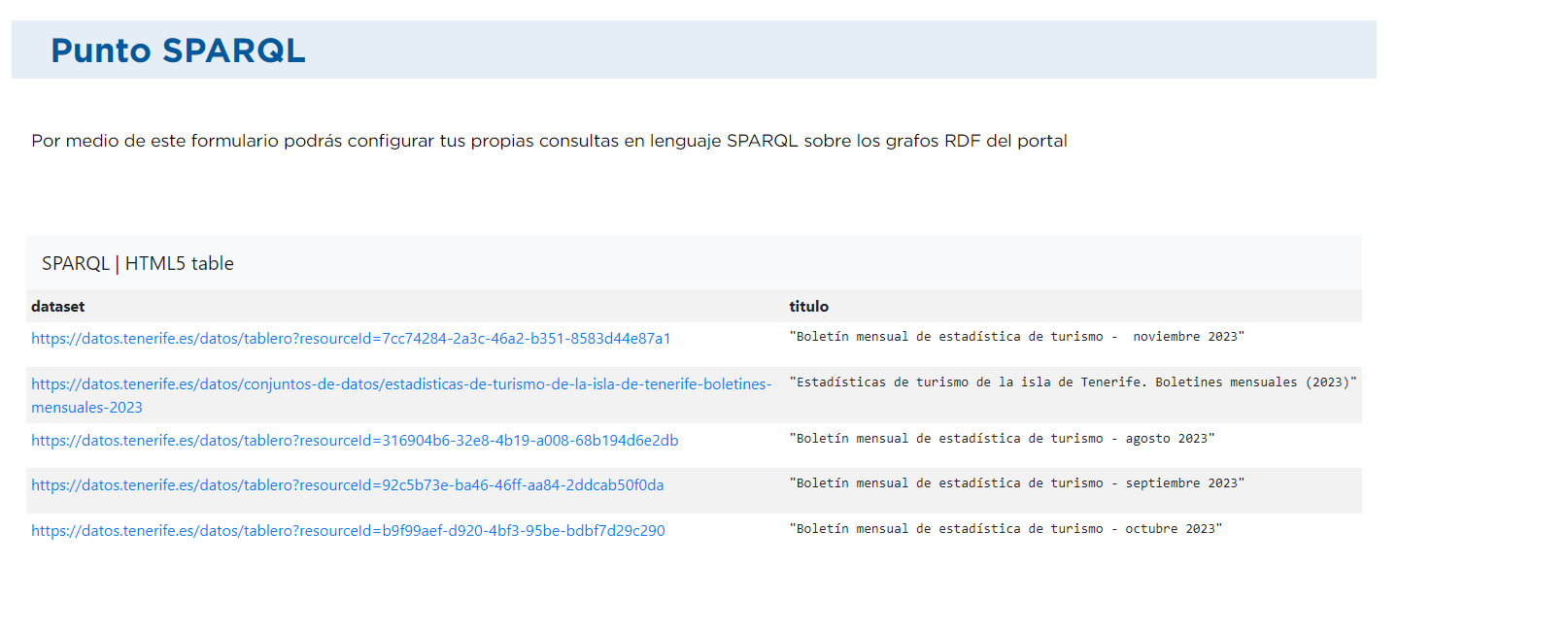
2. Filtrando por cadenas de texto:
En este caso queremos recuperar aquellos conjuntos que tengan la palabra “turismo” en su título (?title):
PREFIX dct: <http://purl.org/dc/terms/>
PREFIX dcat: <http://www.w3.org/ns/dcat#>
SELECT *
WHERE {
?dataset dct:title ?titulo .
FILTER (CONTAINS(LCASE(?titulo), "turismo"))
}
El resultado sería este:
3. Buscar un conjunto o recurso por su nombre concreto:
Obtener las URL de los conjuntos de datos o recursos con título “Paradas de guagua”
PREFIX dct: <http://purl.org/dc/terms/>
SELECT *
WHERE {
?URL dct:title "Paradas de guagua"
}

4. Filtrar por tipo de recurso
En el portal de datos abiertos un conjunto de datos puede tener un mismo recurso en varios formatos (distribuciones), por lo que al consultar en el punto SPARQL obtendremos resultados repetidos con el mismo título, que podemos diferenciar añadiendo una columna de tipo de recurso.
En la siguiente consulta buscaremos mediante la cláusula FILTER aquellos conjuntos que tengan la palabra “centros” y obtendremos sus enlaces, títulos y formatos:
PREFIX dct: <http://purl.org/dc/terms/>
SELECT
WHERE {
?URL dct:title ?titulo.
?URL dct:format ?formato .
FILTER (CONTAINS(LCASE(?titulo), "centros"))
}
order by asc(?titulo)
También existe la posibilidad de filtrar para obtener solo los recursos de tipo GeoJSON.
En este caso, hay dos formas de búsqueda, cuyo resultado sería el mismo:
Usando FILTER:
PREFIX dct: <http://purl.org/dc/terms/>
SELECT *
WHERE {
?URL dct:title ?titulo.
?URL dct:format ?formato.
FILTER (CONTAINS(LCASE(?titulo), "centros"))
FILTER (CONTAINS(LCASE(?formato), "geojson"))
}
Indicando la cadena de texto en la tripleta:
PREFIX dct: <http://purl.org/dc/terms/>
SELECT *
WHERE {
?URL dct:title ?titulo.
?URL dct:format "GeoJSON"
FILTER (CONTAINS(LCASE(?titulo), "centros"))
}

5. Obtener información sobre el publicador de los datos:
Esta información aparece recogida en el campo dcat:contactPoint. En la siguiente consulta vamos a recuperar aquellos conjuntos cuyo publicador o punto de contacto sea el Servicio Técnico de Agricultura y Desarrollo Rural (AgroCabildo):
PREFIX dct: <http://purl.org/dc/terms/>
PREFIX dcat: <http://www.w3.org/ns/dcat#>
SELECT distinct ?URL ?titulo ?punto_contacto
WHERE {
?URL dct:title ?titulo.
?URL dcat:contactPoint ?punto_contacto.
FILTER (CONTAINS(LCASE(STR(?punto_contacto)), "servicio técnico de agricultura"))
}
ORDER BY ASC(?titulo)

Hasta aquí la formación sobre el Punto SPARQL de datos.tenerife.es , pero te animamos a seguir conociendo más sobre nuestro portal y todas las posibilidades que ofrece.