


Actualización automática de datos dependiendo de su publicación en el portal
El Portal de Datos Abiertos del Cabildo de Tenerife permite consultar o descargar los conjuntos de datos más recientes de manera automática o manual.
Para disponer de un histórico actualizado debemos seguir una serie de pasos. Dependiendo de cómo se actualizan los datos en el portal, podemos distinguir tres casuísticas:
1. Mismo conjunto de datos y mismo recurso
De los tres casos a contemplar este es el más directo, ya que solo depende de una URL. Una vez localizado el recurso del conjunto de datos, podemos utilizar la herramienta que prefiramos para que obtenga los datos a través de la URL del recurso. Para obtener dicha URL podemos utilizar dos métodos.
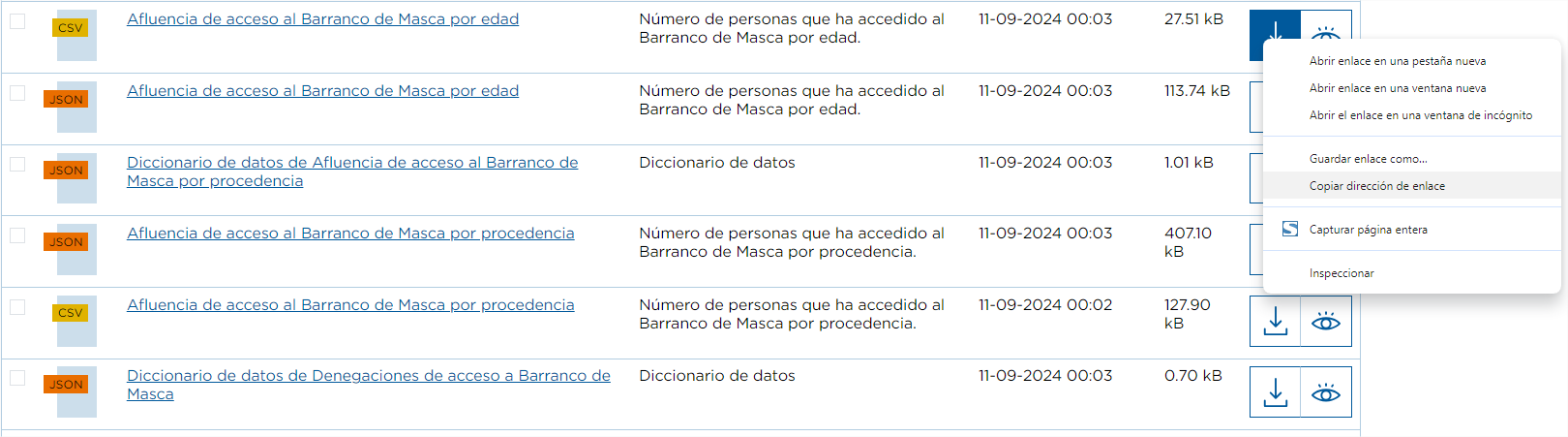
El primer método, y el más sencillo, consiste en dar con el botón derecho del ratón sobre el botón de descarga del recurso y seleccionar la opción Copiar dirección de enlace.
Por ejemplo, este caso es el del conjunto de datos “Afluencia a Barranco de Masca”. Este conjun
to tiene el recurso “Afluencia de acceso al Barranco de Masca por edad” donde se van registrando el número de personas que ha accedido al Barranco.
Realizando los pasos anteriores, copiaríamos su URL que es:
Si esta URL la utilizamos directamente en el navegador descargaríamos el recurso y, por ejemplo, también la podríamos utilizar como origen de datos en un informe de Power BI para que al actualizarlo recupere siempre los últimos datos disponibles.
En este ejemplo hemos seleccionado el formato CSV, pero podríamos hacer lo mismo con cualquier otro tipo de formato.
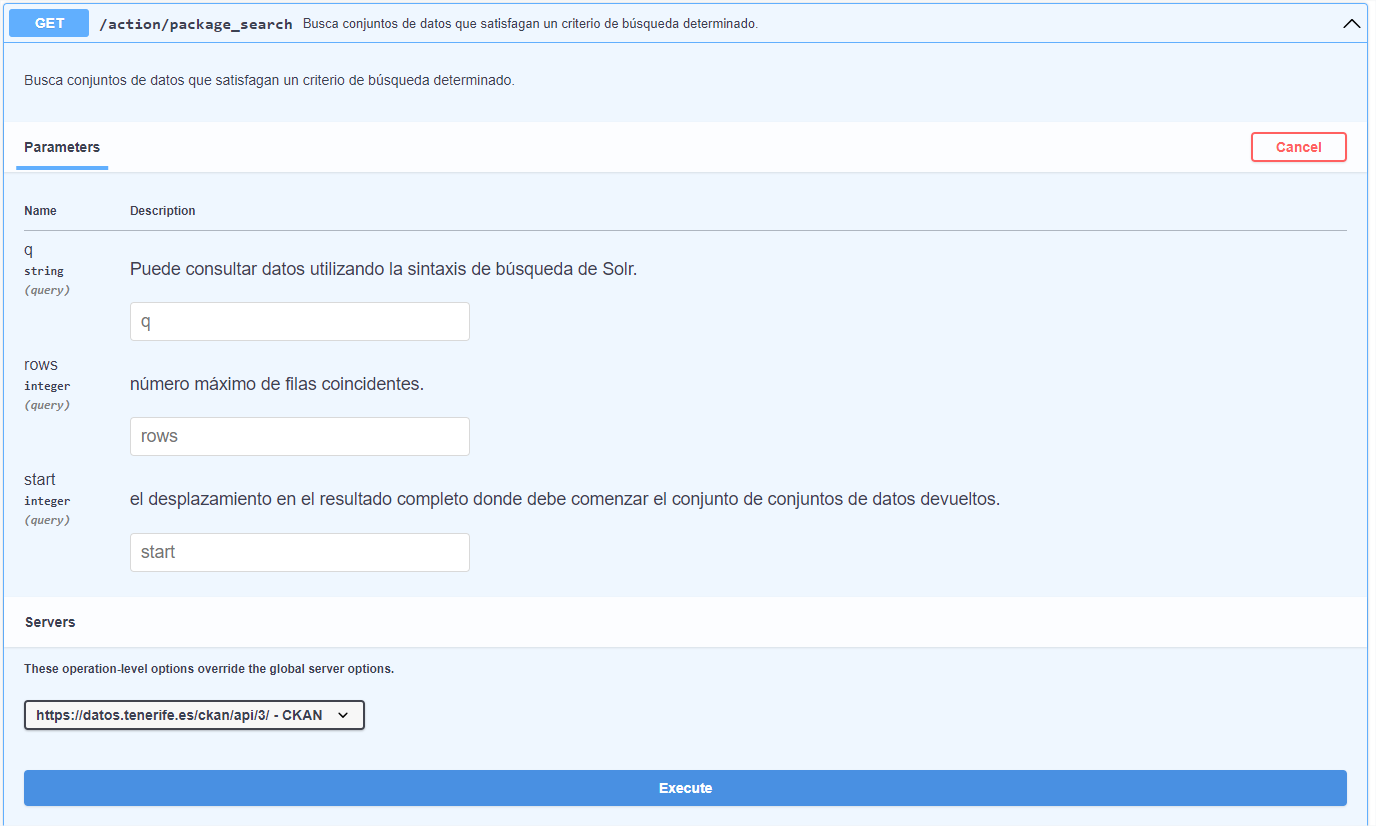
El segundo método para obtener el enlace necesario para la descarga es mediante la API del portal, que se encuentra en el bloque de Datos.

De todos los endpoints que aparecen utilizamos “package_search” del apartado “Conjuntos de datos”. Este endpoint busca los conjuntos de datos que satisfagan la búsqueda y muestra en formato JSON los metadatos asociados al conjunto de datos, junto con los recursos de los que dispone. Después de pulsar el botón de “Try it out”, indicaremos el nombre del conjunto de datos a buscar “Afluencia a Barranco de Masca” en el parámetro “q” y le daremos al botón “Execute”.
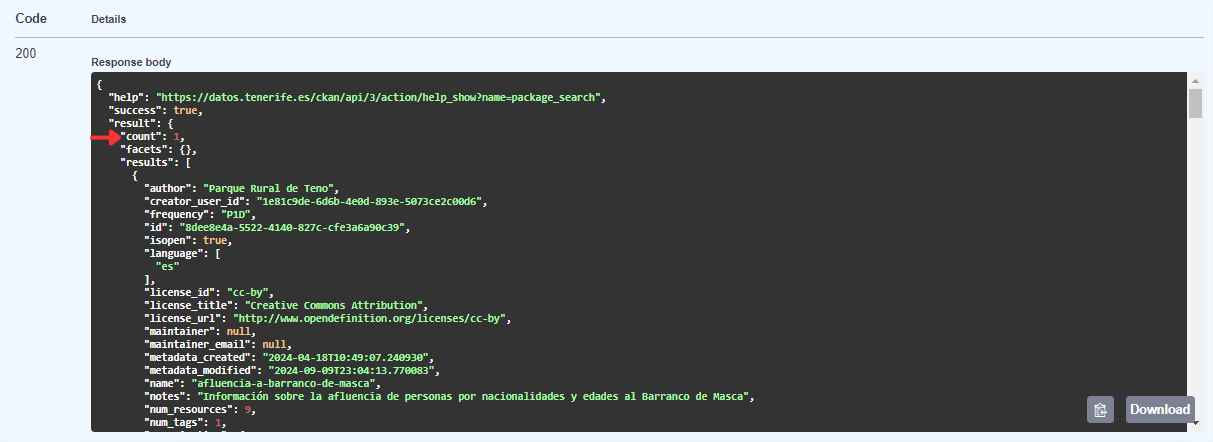
En primer lugar, además de comprobar que no ha habido errores (código 200), podemos ver cuántos conjuntos de datos satisfacen nuestra búsqueda, en este caso 1.
Según vamos bajando por el resultado podemos ver los diferentes metadatos del conjunto, por ejemplo, su título (title) o la descripción (notes) entre otros.
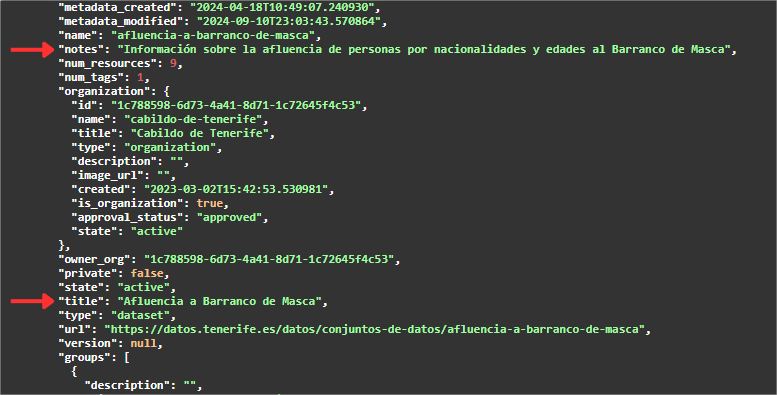
Si seguimos bajando por el JSON encontraremos un array ("resources": [ ]) con todos los recursos de los que dispone dicho conjunto de datos. Para una mejor visualización o utilización se permite la descarga de dicho JSON.
A continuación, debemos buscar el valor asociado a la etiqueta “url” del recurso que tenga como metadatos:
- "name": "Afluencia de acceso al Barranco de Masca por edad"
- "format": "CSV".

A continuación, debemos buscar el valor asociado a la etiqueta “url” del recurso que tenga como metadatos:
- "name": "Afluencia de acceso al Barranco de Masca por edad"
- "format": "CSV".
Y de esa forma obtenemos la misma URL para el recurso que la que obteníamos con el primer método. Con este segundo método podríamos averiguar en una única llamada a la API las URL de varios recursos a la vez, si fuera necesario.
2. Mismo conjunto de datos y distintos recursos
Si en el caso anterior dependíamos de una única URL y el proceso de obtención podía hacerse de forma manual (debido a que solo se actualiza un recurso), en este caso, es interesante un proceso de automatización que obtenga todos los recursos necesarios para conformar un histórico.
Por ejemplo, en el conjunto de datos “Reservas de actividades en la naturaleza en Tenerife” los recursos se dividen por años, mostrando la cantidad de personas que realizan una actividad en una fecha determinada, por lo que deberíamos obtener todas las URL de los recursos (escogiendo el formato deseado) desde el primer año para el que existen datos, 2016.
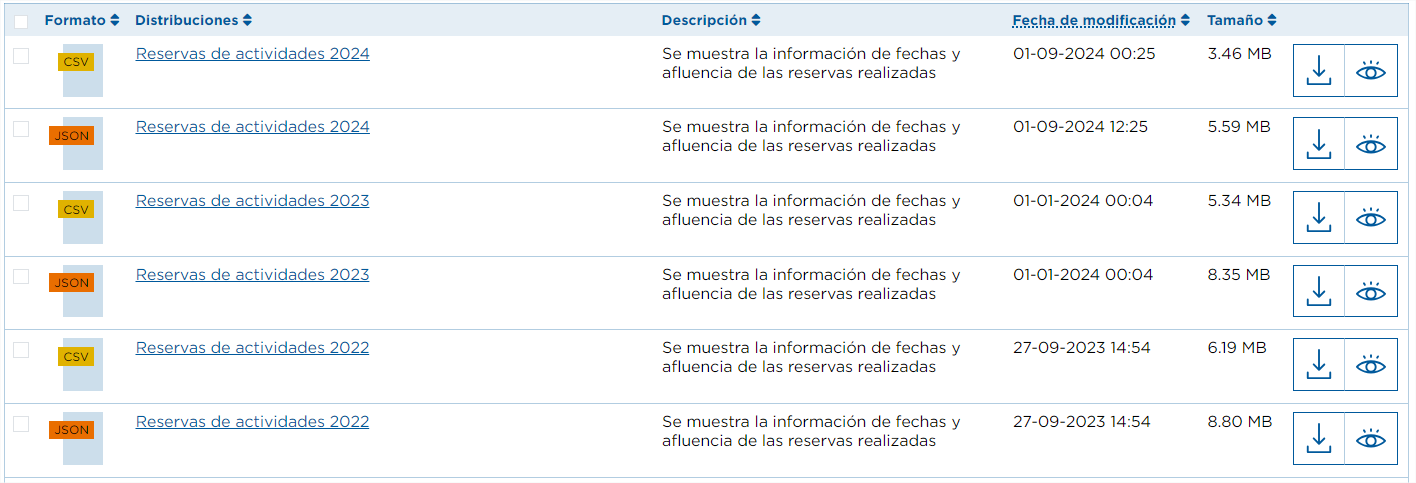
Para el proceso de automatización debemos repetir los pasos indicados anteriormente:
- Utilizar el endpoint “package_search” del apartado “Conjuntos de datos”, en la API del portal que encontramos en el bloque de Datos.
- En el parámetro “q” indicar el nombre exacto del conjunto de datos a buscar, entrecomillado (es decir, "Reservas de actividades en la naturaleza en Tenerife") o una o más palabras para realizar la búsqueda (por ejemplo, Reservas actividades naturaleza).
- Verificar que obtenemos resultados y, si hay más de uno quedarnos con aquel array de resultados cuyo title coincida con el nombre del conjunto de datos.

- Por último, del array de resources nos quedamos con aquellas URL para las cuales los metadatos de format sean “CSV” y name contenga “Reserva de actividades".
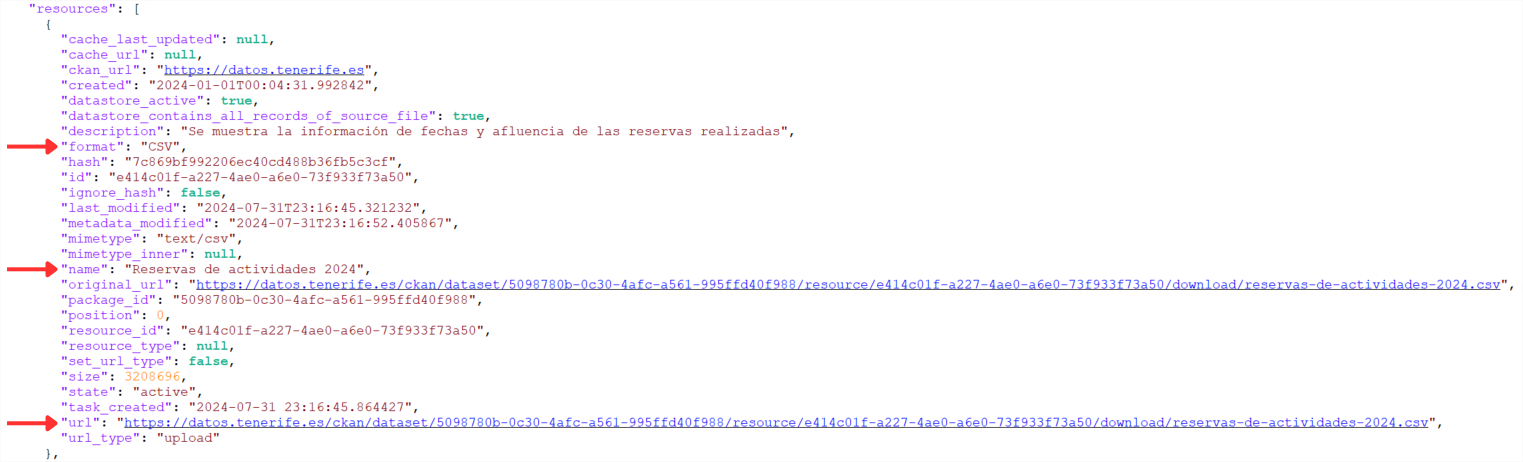
De esta forma, en el momento que se publiquen los datos con las reservas de 2025 podremos recoger también automáticamente la URL del nuevo recurso mediante este proceso, para así poder descargar los datos.
En este caso también podríamos ir copiando las URL manualmente, porque, al fin y al cabo, los recursos están en un mismo conjunto de datos y, simplemente tendríamos que pulsar con el botón derecho del ratón para obtener el enlace. Eso sí, tendríamos que recordar anualmente acceder al conjunto de datos para copiar la URL del nuevo recurso actualizado.
3. Distintos conjuntos de datos
En este caso tenemos distintos conjuntos de datos, pero que tienen la “misma” relación de recursos. Para este caso, no sólo vuelve a ser interesante la automatización, sino también recomendable. Por ejemplo, si estamos interesados en analizar los datos meteorológicos diarios de todas las estaciones de Tenerife, el portal cuenta actualmente con datos para 62 estaciones, cada una de ellas cuenta con recursos anuales hasta 2024, tanto en formato CSV como JSON. Esto supone cientos de recursos, de los cuáles habría que recoger la URL y cada año se incorporan más.
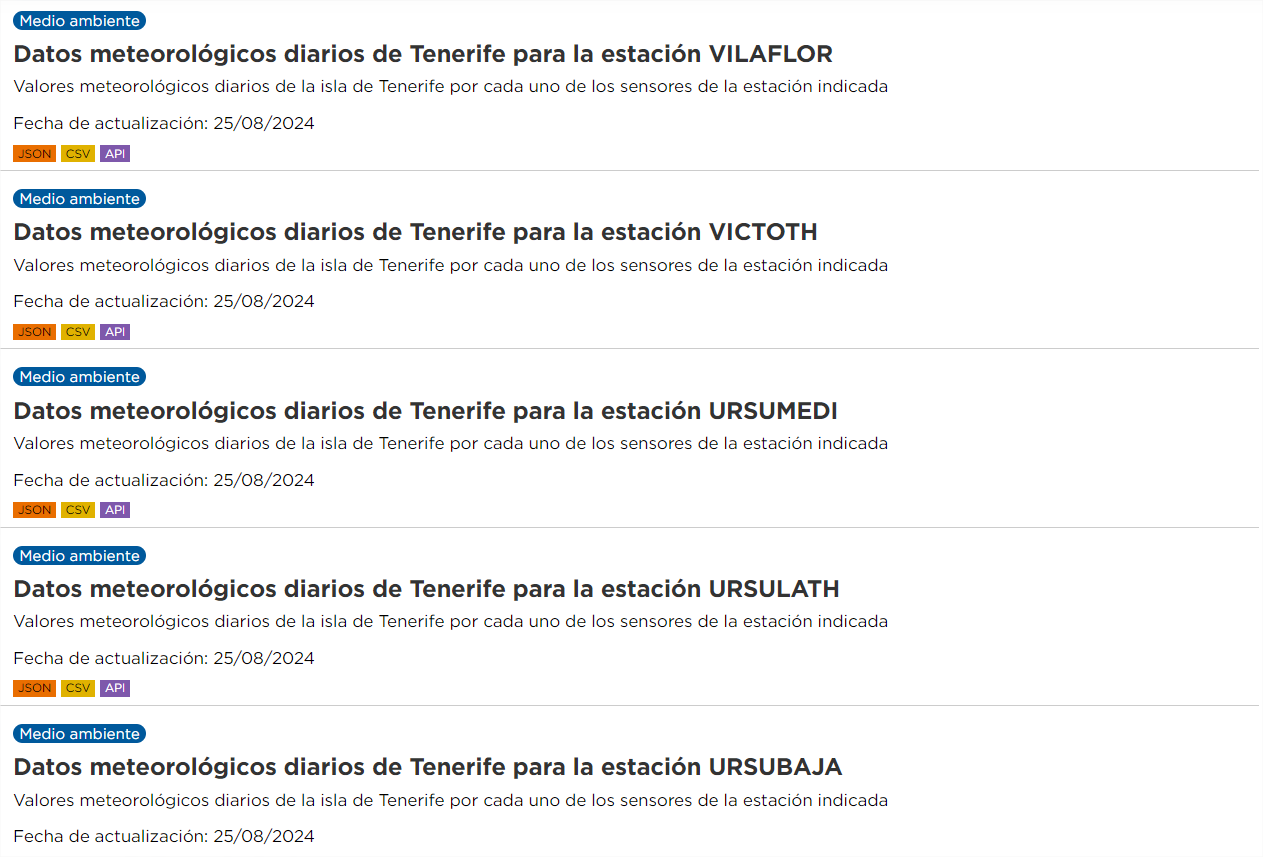
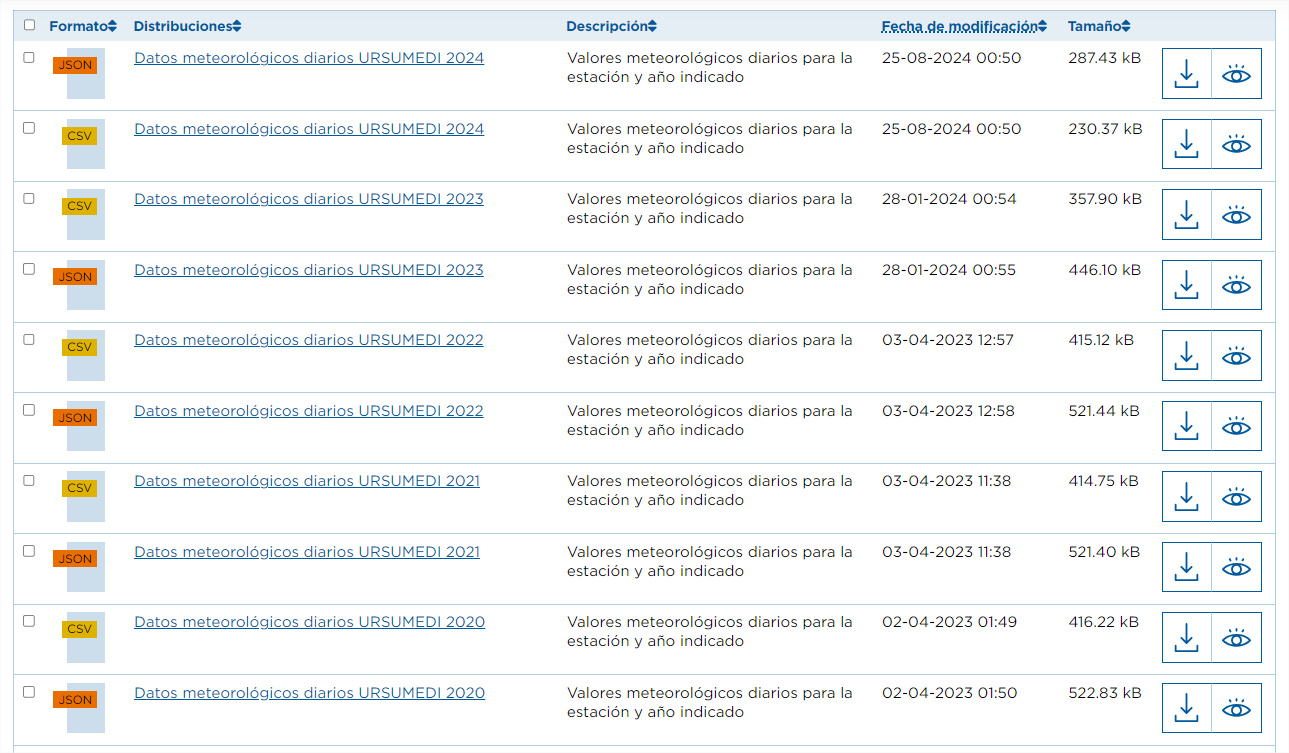
Los pasos a realizar en este caso son los mismos que en el caso anterior, con la salvedad de que el parámetro “q” debe contener un valor genérico, por ejemplo, “Datos meteorológicos diarios” (recordar ponerlo entrecomillado).
Este endpoint está limitado a 10 resultados o conjuntos de datos, por lo que hay que lanzar dicho endpoint modificando el parámetro rows para que nos devuelva más conjuntos.
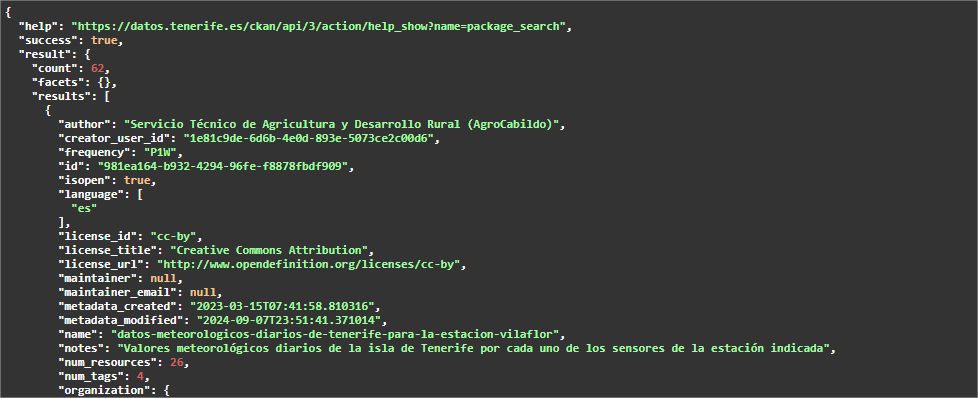
Dado que el número de resultados esperado es 62, podemos indicar en rows, por ejemplo,100. Ya que swagger se utiliza como documentación de la API y el JSON a recuperar es bastante extenso, lo que puede ocasionar problemas de carga en la página del portal, es recomendable lanzar la consulta directamente en otra pestaña del navegador. La URL para ejecutar sería:
https://datos.tenerife.es/ckan/api/3/action/package_search?q=%22Datos%20meteorol%C3%B3gicos%20diarios%22&rows=100
Igual que hicimos en el caso anterior filtraríamos las URL de los recursos cuyo name contenga "Datos meteorológicos diarios” y format sea “CSV”.
Para más información de cómo usar la API del portal de datos abiertos del Cabildo se puede consultar el artículo “API del Portal de Datos Abiertos: consumo de datos de forma automatizada”. Además, está disponible el vídeo sobre cómo utilizar la API del portal de Datos Abiertos.